


“很多人都在关注GPT-5的发布时间,但我更感兴趣的是,哪些应用可以充分利用大语言模型的所有能力。”这是百度创始人、董事长兼CEO李彦宏在第八届VivaTech上,所发表的对于世界人工智能发展的前瞻思考。
近日,第八届“欧洲科技创新展览会”(Viva Technology,简称VivaTech)在法国巴黎凡尔赛门展览中心盛大开幕,吸引了来自世界各地的科技精英和投资者。
作为欧洲最大、最具影响力的科技创新盛会,VivaTech每年都吸引着众多科技巨头和初创企业的参与。今年从法国总统到特斯拉CEO马斯克,再到图灵奖得主Yoshua Bengio等业界翘楚,这些重量级嘉宾的出席使得VivaTech成为科技界的一大盛会。
而今年,李彦宏作为唯一受邀的中国企业家代表,在主论坛“炉边谈话”上与世界分享了中国AI的路线与优势,再次彰显了中国科技企业在全球科技舞台上的重要地位,在VivaTech官方介绍中,将他称为“AI的长期主义者”与“中国AI的头号玩家”。
李彦宏表示“应用的进步,可以推动基础模型的创新,也有助于加快从互联网时代向人工智能时代的转变。”他以百度搜索、直播电商数字人等应用举例说,应用端获取真实的用户需求和问题后,可以持续反馈模型,并由此推进基础模型的技术迭代。”

中国人工智能企业国际话语权渐强
事实上,这并不是李彦宏第一次登上VivaTech的演讲台。早在2016年,李彦宏便曾出席第一届VivaTech大会,就百度创业故事、百度AI发展等话题进行了交流。作为被《时代》周刊评选为全球百大AI人物之一,李彦宏曾与特斯拉CEO埃隆·马斯克、英伟达创始人兼CEO黄仁勋、OpenAI CEO萨姆·奥特曼等人齐名,被誉为全球AI领袖之一,《时代》周刊更将他称为“中国最杰出的未来主义者”。

如今,李彦宏再次登台,表明中国在大模型技术上的实力已经获得全球的认可。自2023年ChatGPT的问世使大模型成为人工智能行业的焦点以来,拥抱这一技术已经成为企业的共识。
早在行业关注大模型这一趋势之前,百度便已进行了技术储备。早在2019年3月,百度就发布了文心大模型1.0版本。这使得百度在2023年3月能够迅速推出文心大模型3.5,成为全球大厂中首家推出大语言模型的企业,并在同年10月发布了文心大模型4.0版本,实现了大模型核心能力的全面提升。李彦宏曾在谈到技术创新的挑战时,表示:“大模型我们走在最前面,我们要勇闯无人区,需要去冒前人没有冒过的风险。”
作为一名长期且坚定的技术信仰者,李彦宏早在30多年前的大学时期,就已学习了人工智能课程。创立百度后,他意识到AI是解决搜索引擎问题的核心技术,因为两者的本质,都是让机器理解人类语言。“所以在十多年前,我们就开始积极投入研发人工智能,尤其是与自然语言相关的人工智能。”
李彦宏的发言展示了百度更向世界传递了中国AI发展的独特优势,不仅代表了百度,也成为中国人工智能产业在国际话语权提升的一个缩影,代表了中国AI产业在AI领域的深厚实力和和发展方向。
中国大模型发展按下“加速键”
近年来,中国的大模型发展进入了一个快速上升的阶段。不仅仅是百度,国内大量的企业也纷纷投身于大模型的创业和开发中。
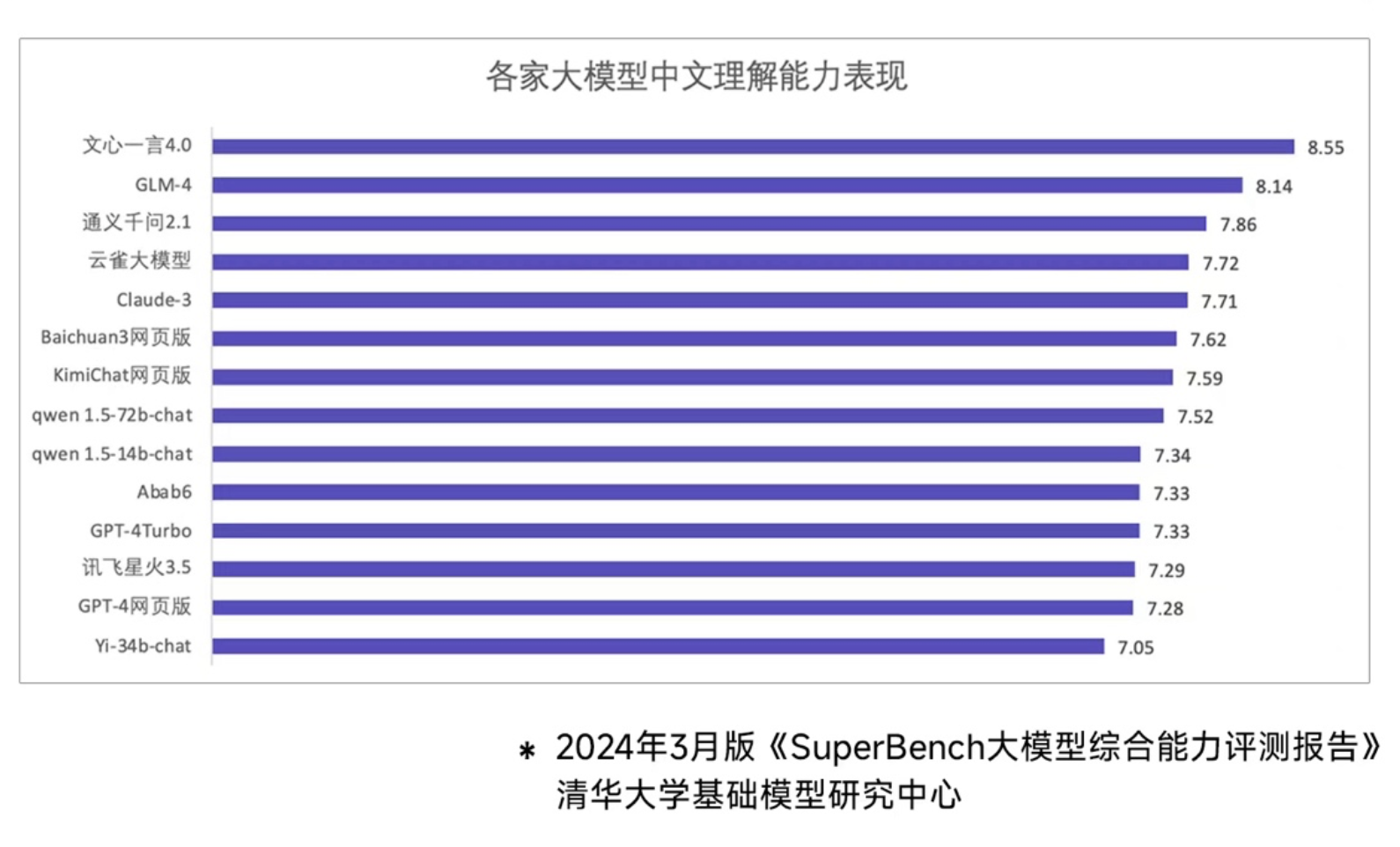
目前,全球各类大模型评测榜单中,国内大模型在TOP10中长期占据半数席位。其中,百度的文心大模型、阿里的通义千问、智谱的GLM-4等更是稳居TOP5。这些大模型在理解、逻辑、记忆等整体能力上保持在世界一流水平,特别是在中文理解与创作方面具有显著优势。
2024年3月,国内人工智能权威机构清华大学基础模型研究中心发布的《SuperBench大模型综合能力评测报告》中,文心大模型4.0在中文理解能力上排名第一,充分证明了中国AI企业在中文处理方面的技术实力和应用能力。这种优势不仅推动了中国AI技术的快速发展,也为中国AI企业在国际市场上赢得了更多机会。
除了技术上的突破,中国AI企业还积极推动人才培养。在Create 2024百度AI开发者大会期间,百度宣布其在2020年提出的“5年为全社会培养500万AI人才”的目标已经提前达成,不仅体现了中国企业在AI教育领域的投入和努力,也为整个行业的发展提供了坚实的人才基础。
在基础模型的数据训练方面,李彦宏表示,超级应用诞生后,还可以促进大量数据生成,为大模型提供更加充沛的训练数据。“有人说,随着模型参数越来越大,我们很快就会用完所有现存的数据,但我认为,当超级应用诞生时,数据会大量生成,所以我并不担心。”
其中,数据工程师的价值不可忽视。数据在大模型训练过程中具有重要作用,数据工程师通过收集、清洗和整理高质量的数据,确保模型训练基础的准确性和相关性,他们在特征工程方面发挥关键作用,通过提取有价值的特征,进一步提升模型性能。
打造最适合中国场景的大模型
大模型的发展最终要落地到产业,产生实际价值。在VivaTech对谈中,李彦宏表示,中国AI与西方的最大区别在于应用,在中国,无论是初创公司、还是互联网大厂,都在努力寻找PMF(产品市场契合度),致力于探索最能发挥生成式AI能力、能被数十亿人使用的应用形态。

丰富的应用场景是中国发展AI的最大优势,中国企业应该充分发挥这一优势,携手共进,让中国AI不仅跻身全球顶级水平,而且实现弯道超车,引领人工智能的发展趋势。
李彦宏表示:“2024年是百度迈向生成式人工智能的第二年,公司正在从以互联网为中心转向人工智能优先,积极推进用文心大模型重构To C和To B业务,利用生成式AI增强用户体验、提升客户效率、提供智能体和应用开发工具,并带来更高效的系列模型。”

目前,百度文心大模型已经在众多行业打造了标杆合作:在ToC领域,与三星、荣耀、蔚来汽车、联想达成合作;在ToB领域,与山源科技打造矿山行业大模型智能应用。
中国的大模型在训练过程中使用了大量的中文语料库,能够更好地理解和生成中文内容,因此在中文处理方面具有天然的优势,更加适合作为中国企业采用大模型的首选。
自然语言是“人工智能皇冠上的明珠”。大语言模型(LLM)和语言息息相关。李彦宏在提到百度基础模型的定位时表示“我们最主要的市场在中国,所以在中文上,我们一定要比世界上任何模型都做得好。现在,文心大模型4.0的中文能力已经超过了GPT-4。”
目前,文心大模型API日均调用量突破2亿次,相较于2023年第四季度财报披露的5000万次计算,日调用量环比增长300%。文心大模型已经成为中国最领先、应用最广泛的AI基础模型。
“很多人都在谈论AGI(通用人工智能),他们说可能还要两年或者五年,”李彦宏感慨,但要真正抵达理想中的AGI时代,“我认为还要十年以上”。
李彦宏在VivaTech的亮相不仅是中国AI产业的一次重要展示,也是中国科技企业走向国际舞台的重要一步。
随着越来越多的中国人工智能企业登上国际舞台,让全球看到了中国AI产业的崛起和进步。相信在不久的将来,中国的大模型企业有望在国际舞台上发挥更重要的作用,引领全球AI技术的发展潮流。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/5433