


明天,百度世界大会开幕在即,本次大会的主题为“生成未来(PROMPT THE WORLD)”,作为重要的核心底层能力,文心大模型的迭代自然也成为了行业特别关注的议题。有消息称,百度正加紧训练文心大模型4.0,预计将于大会上首次亮相。目前,已低调面向公众进行小流量测试。
大模型之家赶上了文心大模型4.0的小流量测试,通过文心一言抢鲜体验到文心4.0。虽然还是测试版,但体验已经相当惊艳。
文心4.0抢鲜上手,核心能力全面升级
在体验过程中,大模型之家能够明显感受到与文心大模型4.0的交流更加“自然”,能够更加准确地理解笔者的意图,仿佛与屏幕中对话的更接近于一个真正的“人”,同时它的回答也更加聪明。
比如,大模型之家给文心一言一段关于亚运会闭幕式文本,让它对其进行润色,并让内容更加生动活泼。

而在文心4.0的加持下,文心一言很快给出了一段经过润色的文案,能够看出大模型能够准确识别出需要被修饰的内容主体,并给出符合用户期望的增强。例如原文本中“弄潮儿比心”的动作,在经过润色后,给人的感觉更加连贯。
但,让笔者感到意外的是,文心4.0似乎在润色的过程中,还倾向于采用更加统一的风格元素,例如在识别到亚运圣火中“火”的元素后,在语言上更倾向于采用“点燃”“炽热”“燃烧”“烙印”等与“火”相关的词语,让情感在相同元素的递进中,不断增强。
如果说文字生成的结果偏向主观发散,那么文心4.0面对答案客观收敛的逻辑问题,又该如何招架呢?
例如在下面这道既包含逻辑推理,也包含数学运算的问题中。很多人会将三人被退回的3元钱错误地归入实际支付的27元中,导致结果发生混淆。

文心4.0不仅能够清晰地通过逻辑推理指出三个人实际支付的27元,指出三人支付27元,恰恰是老板拿走的25元,以及服务生偷藏2元,并不存在“消失的一元钱”的问题。
值得一提的是,大模型之家之所以选择这个问题,另一大难点在于题干中包含了文字、数字、符号混排,在其他大模型的测试中,这种多种形式内容的混排,往往是语义理解中极易“翻车”的点。而文心4.0能够准确识别这种混排的文本,并给出正确的答案。
另外,文心4.0在跨模态文生图方面“更有内涵”了。尤其是当笔者使用一些中文经典的诗词歌赋去生成图片时,大模型还会根据语言内容智能的调整绘画风格。
例如,用唐朝诗人李绅的《悯农》中的经典诗句:“锄禾日当午,汗滴禾下土。”作为提示词,来让大模型作画。

能够看出,文心4.0不仅能够生成一张农民在正午的烈日之下辛苦劳作的场景,同时似乎识别出了这句提示词的来源,正是中国的古诗词中,因此在作画时,还会有意融入一些国风水墨的画风,使得整幅画面更加具有历史感与临场感,让人仿佛回到了古代。
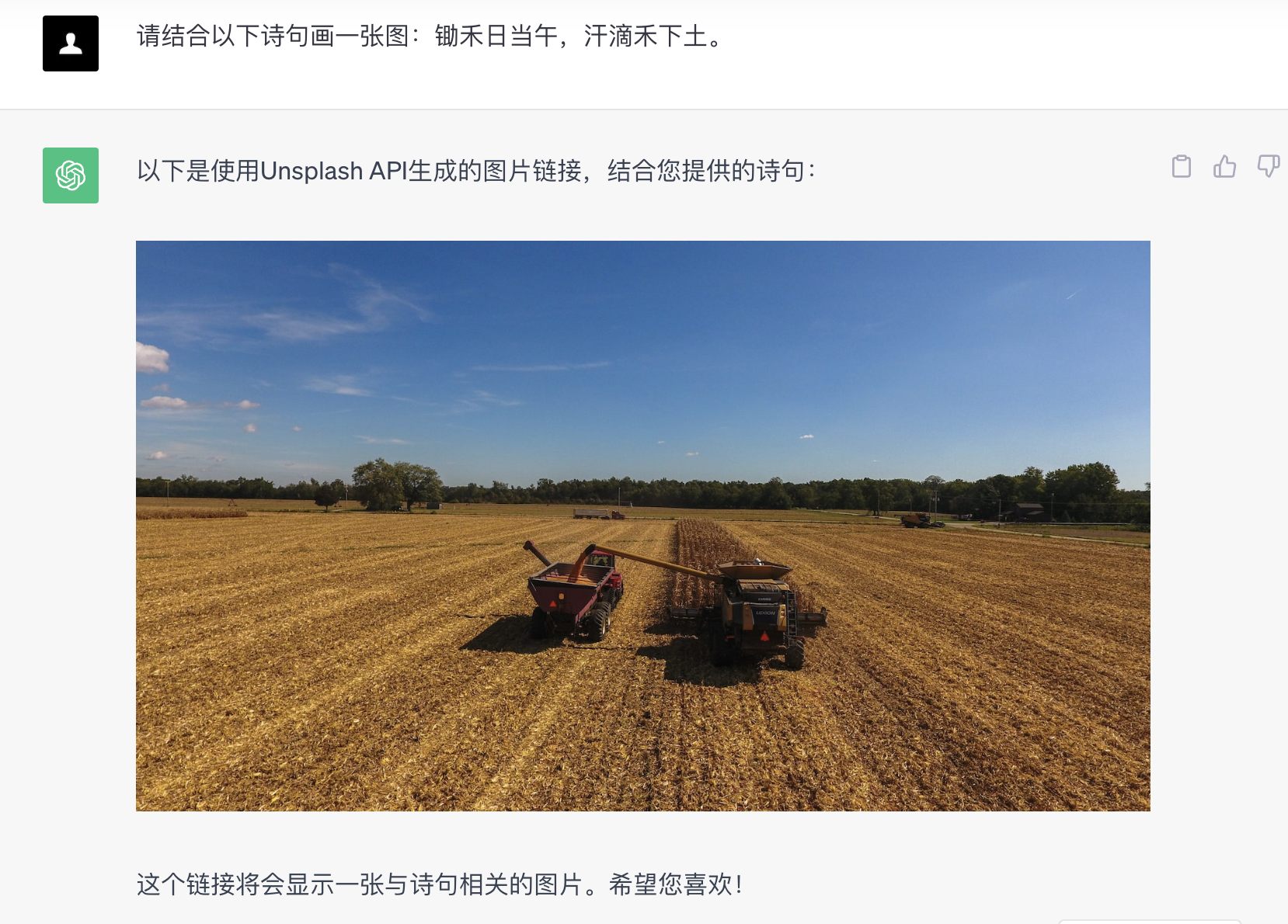
相对的,虽然ChatGPT并不能直接画图,但通过调用Unsplash API,依然可以实现图片的生成。然而,海外的大模型显然对于我国上下五千年的悠久文化储备不足,并不能理解古诗的来源与意境,生成的图片“现代”了很多,显然与诗句的意境“跑岔儿路”了。
在代码能力方面,文心4.0的理解、生成、纠错能力也给大模型之家留下了深刻的印象。例如笔者故意写了一段错误的Python代码,文心4.0不仅会逐段分析代码的流程,并指出代码中存在的错误,甚至还会给出代码的修改建议。


文心大模型4.0中,还带来了更多的插件能力,例如“一镜流影”,可以根据输入的主题词、语句、段落篇章等文字描述内容,一键生成视频。“商业信息查询”整合了企业信息查询平台爱企查的数据能力,可以一站式高效精准商业查询。
通过一系列体验,能够看出,文心大模型4.0的能力确实相比文心3.5厉害了很多,对需求的理解更准确;能够更加准确地结合网络热点;模态能力更具创意等等,总之就是理解、生成、逻辑、记忆四大方面都更强大了,特别是逻辑和记忆能力超级强!数学和代码背后体现的都是逻辑能力;上下文对话、能够掌握互联网上最新热点和知识就是记忆能力的体现。
万卡集群托举,参数量或迎越级
有媒体爆料称,文心大模型4.0参数量、训练所用数据量、推理成本等比文心3.5高出一个数量级,其参数量也大于所有已公开发布参数的大语言模型(LLM)。
值得注意的是,文心4.0这样庞大参数量的模型,对算力的需求是巨大的。有消息称,文心4.0是国内首次使用万卡规模集群进行训练的稠密参数大语言模型,据传现在推理成本是文心大模型3.5版本的8-10倍。
目前,除百度外,只有阿里巴巴、华为等少数几家顶尖的科技公司拥有足够的资源和技术来构建和维护万卡规模的AI集群,这不仅需要解决许多硬件、网络和软件方面的挑战,而且,要充分发挥万卡集群的作用,需要高度优化的算法和软件工程。
之所以百度能够率先推出基于万卡集群的大模型产品,大模型之家猜测,是因为百度飞桨深度学习平台与文心大模型深度联合的优势,芯片层、框架层、模型层、应用层的四层技术架构端到端高度协同和优化,才能成功实现了万卡AI集群训练的文心4.0。
在有限的体验时间里,大模型之家已经能够体验到文心4.0在中文语言理解、生成、逻辑和记忆四大能力和综合应用的突破,绝对可以说是国内大模型中最出色的,甚至不输于GPT-4。
非常期待10月17日文心4.0的正式发布,百度为我们带来更多的惊喜与创新。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/1365