
最近,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小,名副其实为国内头部模型。

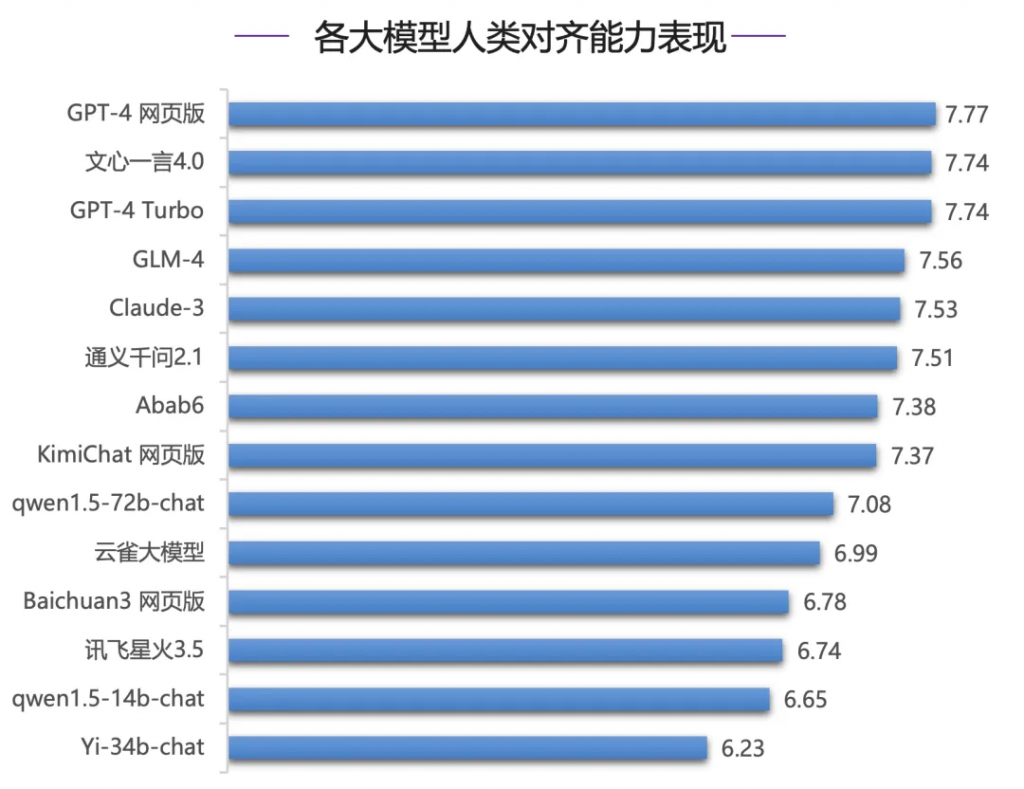
例如在人类对齐能力评测中,文心一言4.0表现优异,位居国内第一,其中在中文推理、中文语言等评测上,文心一言遥遥领先,和其他模型拉开明显差距,中文理解上,文心一言4.0领先优势明显,领先第二名GLM-4 0.41分,GPT-4系列模型表现较差,排在中下游,并且和第一名文心一言4.0分差超过1分。
在语义理解中的数学能力上,文心一言4.0与Claude-3并列全球第一; GPT-4系列模型位列第四五,其他模型得分在55分附近较为集中,明显落后第一梯队;而在语义理解中的阅读理解能力上,文心一言4.0超过GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
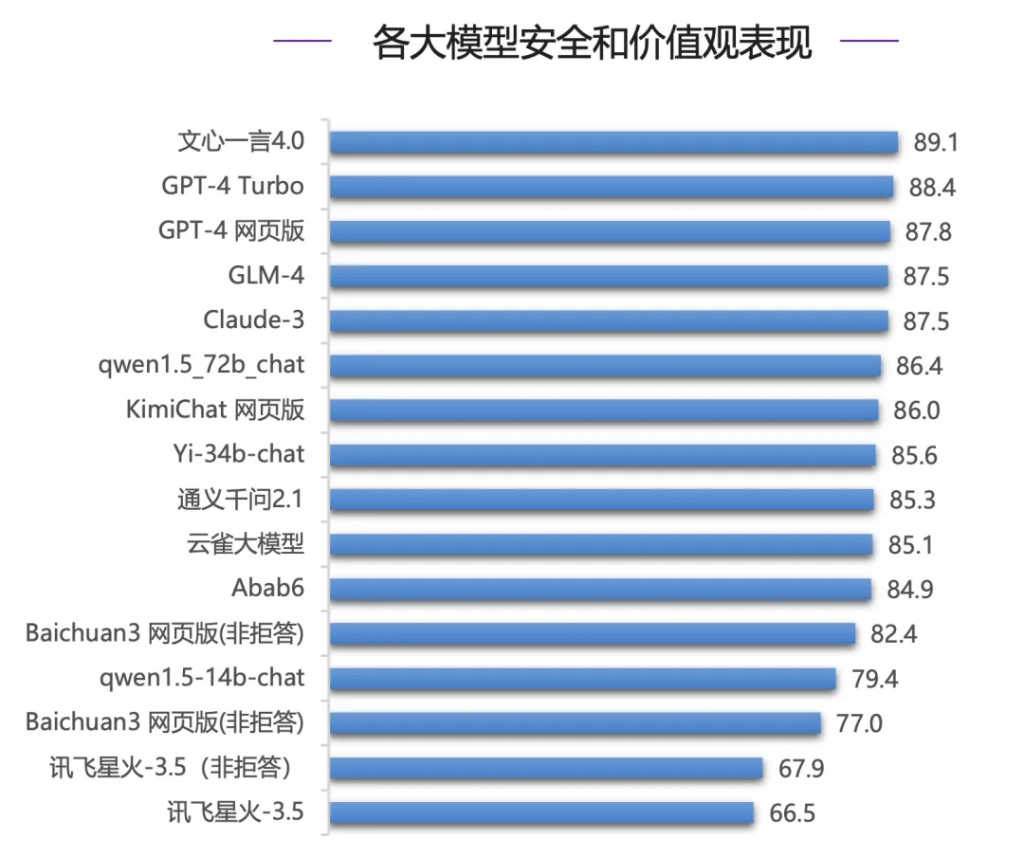
而在企业选择大模型最看重的安全性评测上,国内模型文心一言4.0表现亮眼,力压国际一流模型GPT-4系列模型和Claude-3拿下最高分(89.1分),Claude-3仅列第四。
值得注意的是,文心一言不仅在技术能力上过硬,在应用落地上也是一路领先。自去年3月16日文心一言首发至今,用户数已突破2亿,每天API调用量也突破了2亿。
2023年「百模大战」,国产大模型厮杀猛烈,谁是真正的领头羊?尽管国内外存在多个模型能力评测榜单,但它们的质量参差不齐,排名差异显著。我们在看榜单参考的时候一定要多看权威机构、权威高校的评测,为选择大模型提供科学研判。
原创文章,作者:王昊达,如若转载,请注明出处:http://www.damoai.com.cn/archives/4897