
大模型之家讯 6月30日,百度正式宣布文心4.5系列模型开源。从模型权重、推理代码,到部署套件与技术文档,几乎实现了全流程可复现。这次开源的节奏和姿态都极为主动,透出一种“重构生态主导权”的意图。
文心4.5系列包含10款模型,覆盖47B和3B规模的混合专家(MoE)模型,最大总参数高达424B,外加一款轻量的0.3B稠密模型。全部模型已在 Hugging Face、GitHub 和飞桨星河社区上线,附带详细的技术报告和使用指南,支持多模态任务的从预训练到推理部署全链条实践。

技术根基决定开源底气
文心4.5的核心技术支撑集中在三条主线:多模态MoE模型的结构创新、高效训练推理系统,以及适配产业落地的精调和部署工具。
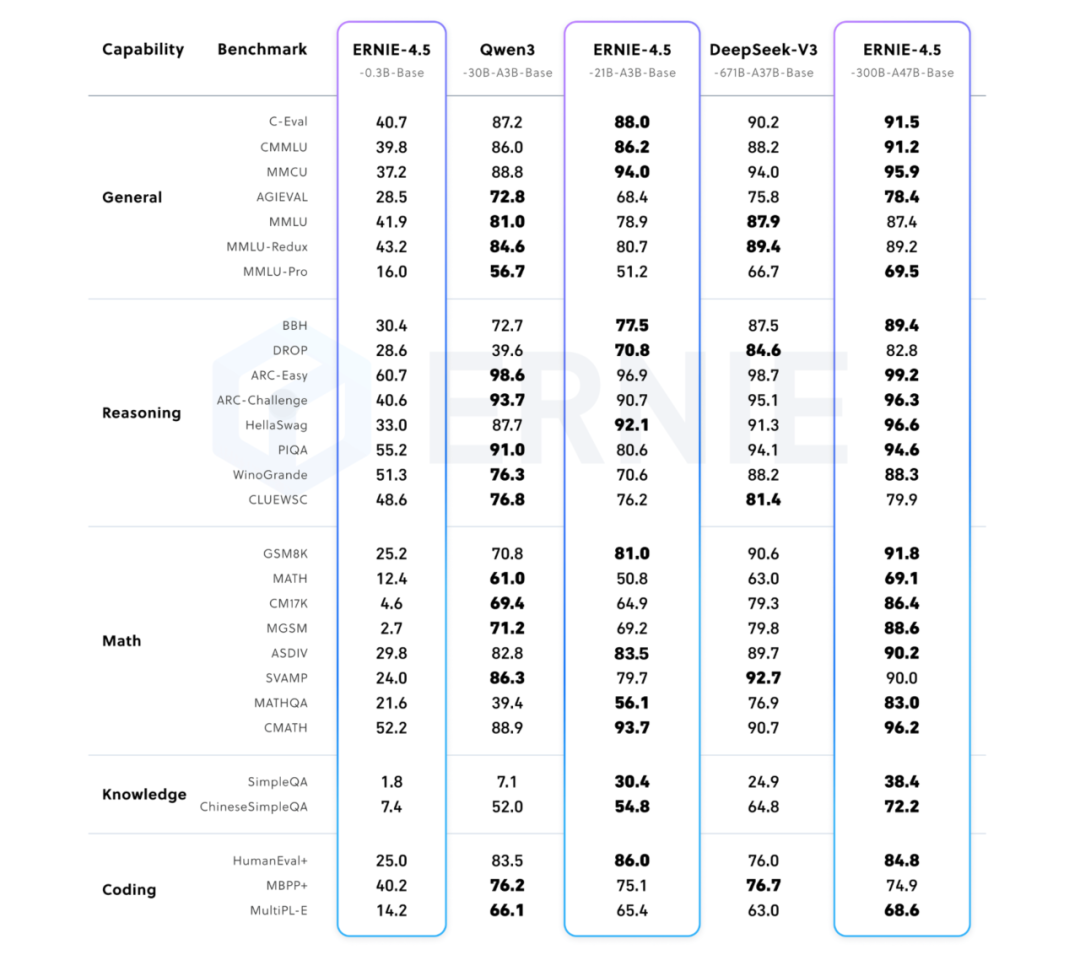
首先是在模型结构上,百度提出了一种异构混合专家架构,强调模态之间的参数共享与独立空间并存。通过多维旋转位置编码和优化后的损失函数设计,文心4.5能够在文本与图像两种模态间实现知识融合,同时保留各自的表达能力。这种结构对多模态预训练尤其关键,为后续的理解和推理任务打下了基础。
其次是训练与推理的效率工程。为了提升MoE模型的FLOPs利用率,团队引入了异构混合并行调度、FP8混合精度训练、流水线重计算等技术,使预训练吞吐量得到显著提升。推理阶段,百度自主设计了4-bit与2-bit量化方案,结合卷积编码、专家并行协同机制,实现近乎无损的压缩效率。模型推理阶段还支持动态角色切换和解码部署分离,大幅降低资源浪费。
这背后,是飞桨深度学习框架作为底座所支撑的系统化能力。无论是在训练阶段的分布式调度、量化策略,还是推理部署时的跨芯片兼容和本地加速,飞桨已经不仅是文心的底层引擎,更是其开源能力的保证。
开放生态的另一种“增长逻辑”
不同于以往仅开放API接口或限制授权的方式,文心4.5这次将包括SFT、DPO、QAT、LoRA等在内的大模型精调流程全面放出。通过文心ERNIEKit开发套件与FastDeploy部署工具,开发者能够实现端到端的模型训练、量化、部署与推理,并可适配多种硬件平台。
百度还配套推出了详尽的使用教程和示例代码,如一键启动训练的脚本配置、vLLM/OpenAI协议兼容部署方式、低比特量化部署范例等,覆盖了从入门到实战的各个环节。星河社区上线的大量实践项目,也为开发者提供了更贴近真实场景的使用案例。
开源并非终点,而是生态的起点。据百度披露,截至2025年4月,文心与飞桨已服务2185万开发者、67万家企业,累计创建模型数量超过110万。此次开源之后,百度还将联合Hugging Face等社区推出系列公开课,并在多个城市启动“文心开源服务站”,通过实地培训和落地项目进一步拉近与开发者群体的距离。

原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/10992