
大模型之家讯 9月19日,小米宣布开源其首个原生端到端语音模型——Xiaomi-MiMo-Audio。这一模型基于自研预训练架构和规模超过亿小时的语音数据,在语音领域率先实现了基于 In-Context Learning(上下文学习,简称 ICL)的少样本泛化,并在预训练过程中出现了可被观察的“涌现”现象。
与预训练相比,后续的训练环节进一步提升了模型在跨模态对齐方面的表现,包括语音对话的自然度、情感表达以及交互适配等能力。研究团队称,这些改进使 MiMo-Audio 在多方面呈现出接近人类的交互水准。
性能对比:开源模型与闭源模型的交锋
在多项语音理解和对话任务的标准评测中,MiMo-Audio 展现出显著性能。根据小米公布的结果,该模型在同等参数量下,超越了其他开源模型,并在 7B 参数规模上取得最佳成绩。
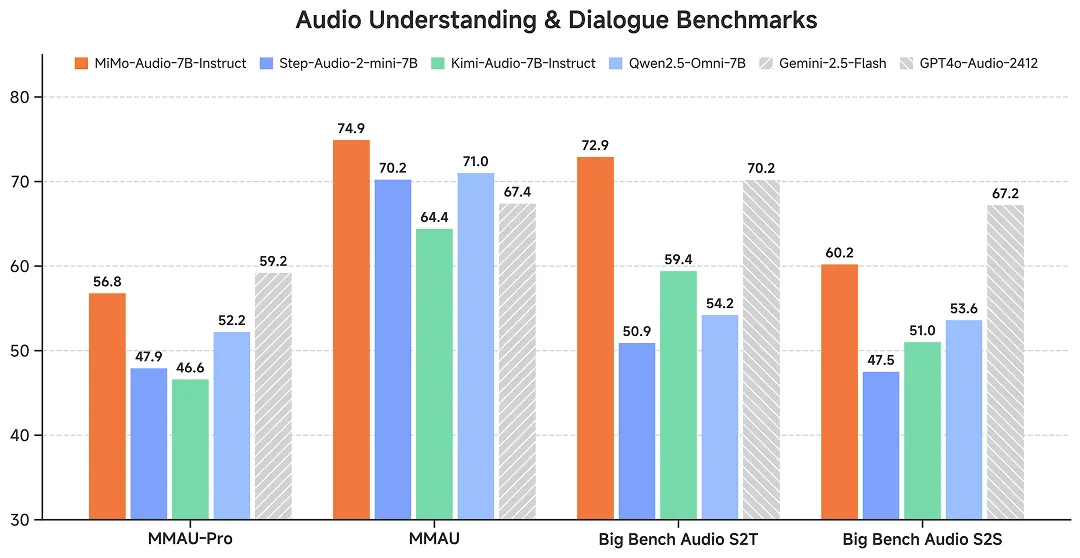

值得注意的是,在 MMAU(多模态音频理解基准)的测试集中,MiMo-Audio 超过了 Google 闭源语音模型 Gemini-2.5-Flash。在 Big Bench Audio S2T 复杂推理任务上,该模型也被评估为优于 OpenAI 的 GPT-4o-Audio-Preview。
多项“首次”与创新贡献
MiMo-Audio 的研究成果被总结为多个“首次”。其中包括首次验证语音无损压缩预训练在扩展至 1 亿小时规模时,能够带来跨任务泛化性和少样本学习能力,被部分研究人员视为语音领域的“GPT-3 时刻”。
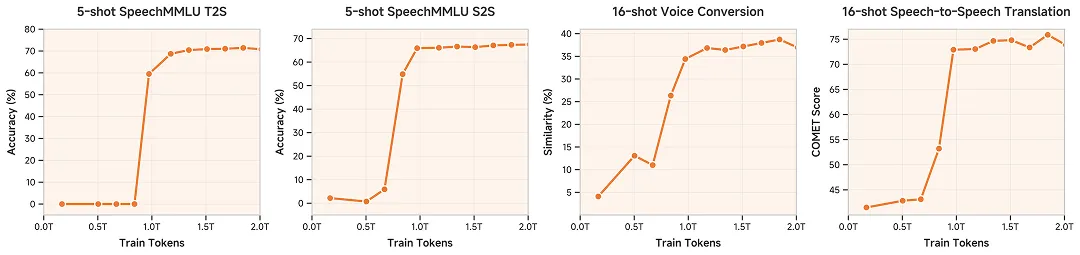
同时,研究团队提出了明确的生成式语音预训练目标和定义,并开源了一整套语音预训练方案,涵盖 Tokenizer、模型结构、训练方法和评测体系,被定位为语音领域的“LLaMA 时刻”。此外,该模型也是首个在开源框架中将“Thinking(思考过程)”同时引入语音理解与语音生成环节的模型。
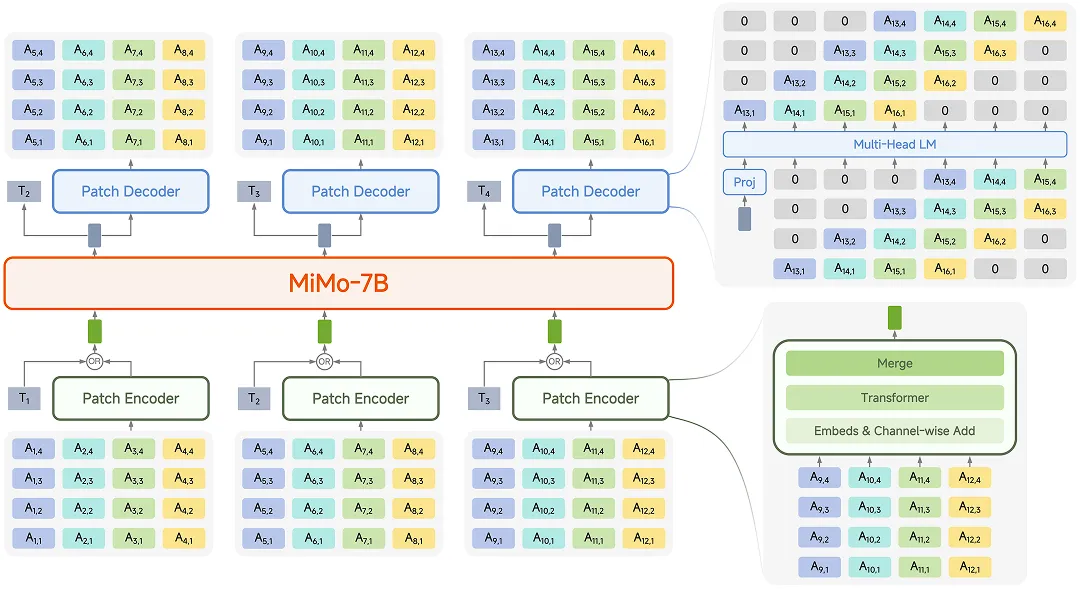
完整开源生态:模型、Tokenizer 与评估框架
此次开源内容不仅包括模型本身,还涵盖完整的技术栈。MiMo-Audio-7B-Base 是首个具备语音续写能力的开源语音模型,而经过轻量指令微调的 MiMo-Audio-7B-Instruct 则在语音理解和生成任务上展现出更强性能,支持通过提示词在 non-thinking 与 thinking 模式间切换,具备强化学习和 Agentic 训练的潜力。
Tokenizer 方面,小米发布了一个 12 亿参数的 Transformer 架构模型,从零训练,覆盖超过千万小时语音数据,可支持音频重建和语音转文本任务。推理代码也同步开源。
同时,小米还公布了完整的技术报告,以及一套覆盖 10 余项任务的评估框架,方便研究者在 ICL 和后训练阶段进行系统测试。
官方认为,MiMo-Audio 的开源将推动语音大模型的研究逐步与语言大模型接轨,并为语音向通用人工智能(AGI)的发展奠定基础。小米表示将保持持续开源的策略,并希望通过开放协作的方式,推动语音 AI 在人机交互领域迈向新阶段。
相关模型、Tokenizer、评估框架及演示案例已上线 Hugging Face 与 GitHub,供研究者和开发者使用。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/12888