


“天下大势,分久必合,合久必分。”
2025年的人工智能赛道,正呈现出一种强烈的分裂感。如果说前几年是“百模大战”的“战国时代”,所有玩家都在同一条“Scaling Law”(规模法则)的跑道上野蛮冲锋;那么2025年,市场则在剧烈的震荡后,清晰地分化出了两条截然相反、却又彼此纠缠的叙事。
一个“向上”,一个“向下”。
“向上”的叙事由行业巨头领衔。不久前,阿里通义Qwen3-Max在多个权威基准测试中成功“登顶”,在被视为最能反映人类综合偏好的LMArena盲测竞技场上,跻身全球前三,一度超越了GPT-5-Chat的特定版本。这是国产大模型首次在性能的“珠峰”上,与OpenAI、Anthropic等全球顶级玩家实现了真正意义上的“同框竞技”。这是“规模叙事”的延续,是“大力出奇迹”的阶段性胜利。
“向下”的叙事则由技术新贵驱动。几乎在同一时间,DeepSeek发布了其最新的DeepSeek-V3.2-Exp模型,在性能与前代旗舰保持相当的前提下,API价格悍然“腰斩”,降幅超过50%。尤其在输出端,价格从12元/百万Tokens骤降至3元/百万Tokens。这场价格战的背后并非是“流血补贴”,而是一场由底层技术突破发起的“成本突破”。
这不是偶然的巧合,而是两条路线的必然碰撞。一方在不计代价地推高智能的“天花板”,另一方在不遗余力地击穿成本的“地板”。
这场关乎“极限性能”与“极致普惠”的博弈,正在重塑AI的商业逻辑。它所激发的矛盾,比模型参数本身更值得深思:当“规模”遭遇“效率”,当“开源”挑战“闭源”,当“中小企业的狂欢”遭遇“头部巨头的利润保卫战”,这场战争的“中场”,究竟在走向何方?
“登顶”的执念:AI巨头的“3A游戏”
对于巨头而言,似乎都对于一路陪伴走来的“Scaling Law”抱有执念,不断探索着规模与能力的边界。
例如,Qwen3-Max的出现,即是对“参数竞赛”有效性的强力背书。在AI领域,“规模”一度是通往更高智能的唯一信仰。Qwen3-Max正是这一信仰的产物。
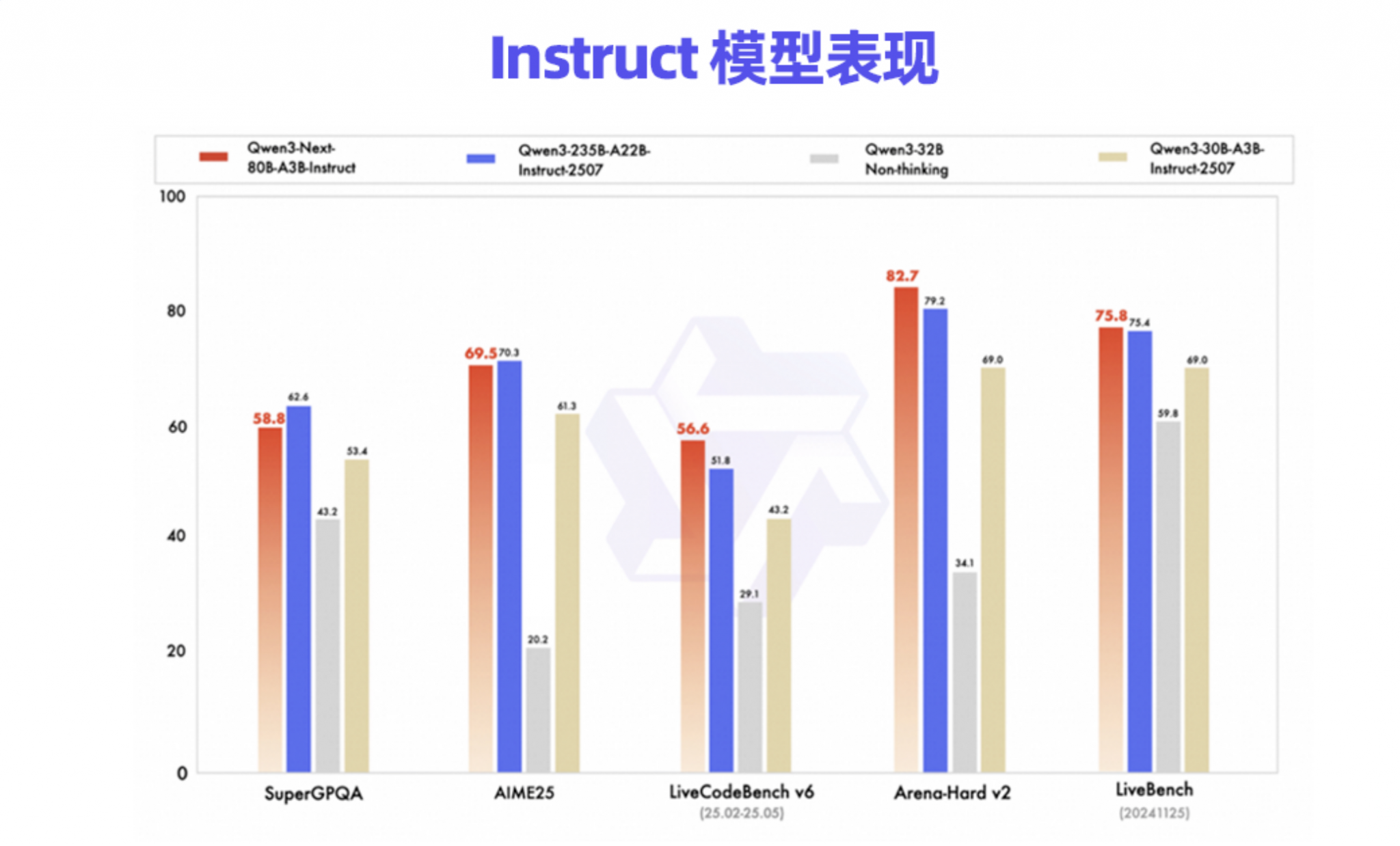
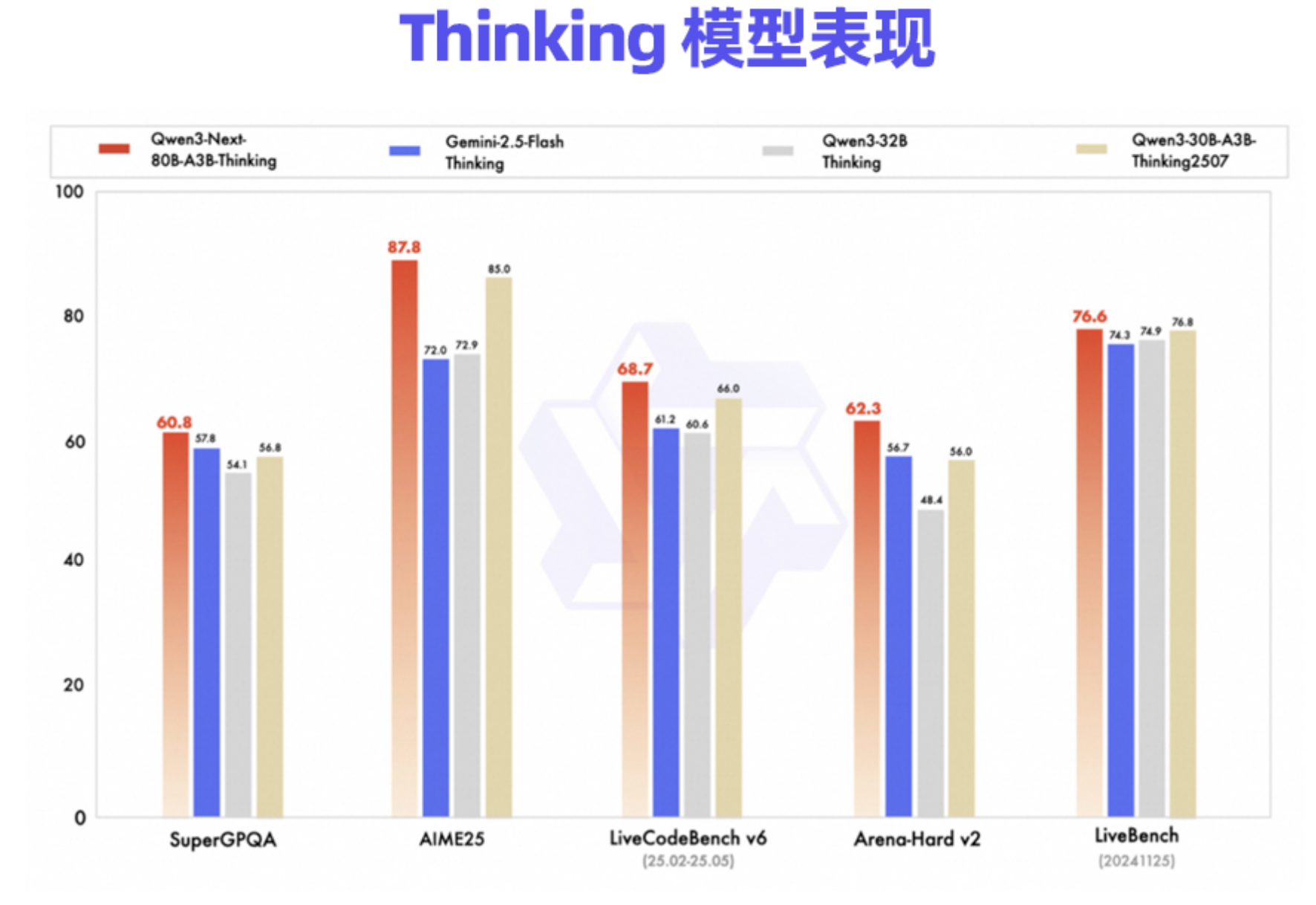
根据多方分析和披露,Qwen3-Max是一个参数量达到万亿级别的“庞然大物”,而巨大的体量也着实为其带来了相匹配的实力:在SWE-Bench Verified上获得了69.6分的世界级成绩;在考验Agent能力的Tau2-Bench上,超越了Claude Opus 4;在AIME等高难度推理任务上,其“Thinking”变体甚至取得了惊人的满分或接近满分的表现。
阿里不惜投入巨量资源,将Qwen3-Max推向SOTA,其战略意图清晰而坚定。这本质上是一场只有巨头才能玩得起的“3A游戏”。
正如在游戏行业,3A大作意味着高昂的开发成本、顶级的制作水准和庞大的宣发资源,大模型领域的“规模竞赛”亦是如此。它是通过人力、财力、物力的极致堆砌,构建起一道后来者难以逾越的性能壁垒和算力门槛。 目的很明确:在AGI的终极叙事中,必须手握一张能与OpenAI平起平坐的“王牌”,借以巩固自身(尤其是云业务)的优势,最后再依靠规模化应用实现盈利。在企业客户选择云服务商时,一个“全球第三”的旗舰模型,其象征意义和信任背书价值千金。
然而,这场“登顶”的盛宴之下,潜藏着“参数陷阱”的冰冷现实。
第一个冲突在于“规模”与“成本”的边际效益。万亿参数带来了性能的提升,但也带来了指数级增长的训练成本和推理成本。根据阿里云官网公布的价格,Qwen3-Max(0-32K档)的输入价格约为8.64元/百万Tokens,输出价格更是高达43.2元/百万Tokens。这种定价,注定了它只能是少数头部企业在核心、高价值场景中才能负担的“奢侈品”。当性能提升的边际收益,开始难以覆盖其高昂的推理成本时,“规模竞赛”就触碰到了商业落地的“玻璃天花板”。
第二个,则是开源策略与商业变现的矛盾。在国内AI赛道中,“开源”正在成为行业的大势所趋,然而矛盾在于,当一个性能“足够好”的开源模型可以免费、私有化部署时,有多少开发者还愿意为其闭源的、价格高昂的模型支付溢价?开源模型虽然“教育”了市场,却也亲手“稀释”了其旗舰API的商业价值。
“破价”的利刃:创业公司“另辟蹊径”的效率革命
一方面是巨头的“3A游戏”,那么另一方面,以DeepSeek的“破价”则是资源相对薄弱的创业公司被迫选择的“另辟蹊径”。
财力雄厚的巨头可以豪赌Scaling Law,但对于创业公司而言,除非拥有OpenAI那样能撬动千亿美元的战略合作,否则在“参数陷阱”面前几乎没有试错空间。 它们唯一的活路,就是通过极致的技术优化——从架构到算法再到工程——在有限的算力里“挤”出更多的能力,为自己,也为客户“挤”出宝贵的利润空间。
而对于DeepSeek而言,从其声名鹊起,便是因为它的“破价”之所以在行业内引发地震,因为它不是“补贴换市场”的互联网旧剧本,而是由硬核技术驱动的“效率革命”。
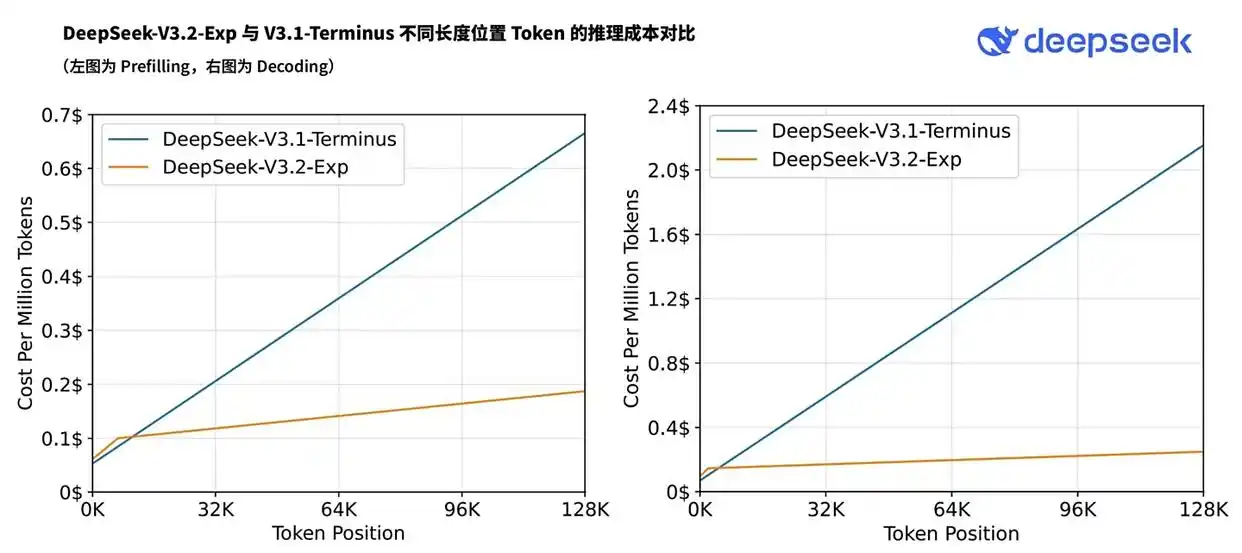
据了解,DeepSeek能够有降价50%以上的底气,来自于一个关键的技术突破:DSA(DeepSeek Sparse Attention)。
在传统Transformer架构中,注意力机制的计算复杂度是O(n^2)(n为序列长度),即每个Token都要和上下文中的所有其他Token进行计算。在处理长文本时,这种“全局关注”会带来灾难性的算力消耗。
DeepSeek V3.2-Exp(总参数量671B,激活参数37B的MoE模型)则彻底重写了这一规则。DSA机制通过引入“Lightning Indexer”(闪电索引器)和“fine-grained selector”(细粒度选择器),实现了两阶段的智能筛选。它不再“蛮力”地关注所有内容,而是像一个高效的速读者,先快速索引、评估上下文的重要性,然后只让当前Token与那些“真正相关”的Token进行精细计算。
其结果是,在处理长文本任务时,DSA“极大减少了每层处理的Token数量”,从而“大幅削减了推理成本和处理时间”。最关键的一点是,根据DeepSeek的官方评测,V3.2-Exp的性能与V3.1-Terminus保持在同一水平。
这彻底改变了游戏的性质。DeepSeek证明了,通过算法和架构的极致创新,可以在不牺牲模型质量的前提下,将推理成本压缩一半甚至更多。
这是对“规模派”的一次精准“降维打击”。它向市场传递了一个清晰的信号:AI的竞争,已经从单纯比拼“肌肉”(参数规模)的1.0时代,进入了比拼“神经效率”(算法与工程优化)的2.0时代。
夹缝中的“新大陆”:API价格战与巨头的“利润保卫战”
高阶模型所形成的巨大价格鸿沟,正是当前AI产业核心矛盾的爆发点。在这道鸿沟的两侧,是中小企业和巨头们截然不同的命运。
对于数以万计的中小企业、初创公司和独立开发者而言,以DeepSeek为代表的“技术破价”无异于开辟了一片“新大陆”。在此之前,AI应用的成本是一只“拦路虎”,如今结束技术手段,正将AI的成本属性从“咨询费”拉向“水电费”。当API成本降低50%甚至90%时,AI应用的“可行性”就可以完成“从0到1”。
正如行业分析师所指出的,DeepSeek的低成本创新,正在推动AI应用“从头部企业垄断转向长尾场景渗透”。这符合“杰文斯悖论”(Jevons Paradox)的经典逻辑:技术效率的提升(成本降低)并不会减少总消耗,反而会因为门槛的降低而激发海量的、前所未有的新需求,最终带来算力总需求的爆发式增长。
然而,中小企业的狂欢,映衬出的却是头部巨头的焦虑。DeepSeek的“技术破价”更是将这场冲突推向了高潮。
事实上,一场残酷的“API价格战”早已在国内AI巨头(如阿里、百度、腾讯、字节)之间打响。早在2024年,字节豆包的“白菜价”就已迫使阿里云(Qwen-Long降价97%)和百度(文心两大主力模型免费)仓促应战。巨头们不惜大幅降低API单价,甚至将中小型模型免费,其核心目的就是“抢占AI云市场”的入口。 他们试图用“模型补贴”换取“云客户”,将用户锁定在自己的生态高墙内。
这场“价格战”与“效率战”的叠加,让巨头们陷入了经典的两难困境。
一位不愿透露姓名的大模型头部企业从业者在一次模拟采访中这样表述:“我们内部现在很分裂。一方面,你必须跟进(降价),市场份额丢了就再也回不来了,云业务的增长指望着这个。另一方面,旗舰模型(如Qwen3-Max)的推理成本是实打实的,降价就是‘割肉’。”
“我们现在的策略是分裂的:用免费的中小模型去‘跑量’,稳住开发者生态;同时用顶尖的旗舰模型去‘立标杆’,服务那些真正愿意为0.1分性能提升付费的头部客户。”但在靠效率的创业公司的“搅局”之下,巨头用‘规模’砸出来的性能溢价,正在被他们迅速拉平。
这段基于行业普遍现状的模拟表述,精准地道出了巨头的“利润保卫战”有多么艰难。他们试图用“云服务+模型”的生态绑定构建“护城河”,但在绝对的性价比面前,这种绑定的吸引力正在受到严峻考验。
超越“规模”与“效率”,AI价值正被再定义
Qwen3-Max的“登顶”和DeepSeek V3.2-Exp的“破价”,看似是两条背道而驰的路线,但它们联手导演的这场“极限冲突”,实际上共同终结了大模型竞争的“蛮荒时代”,并提前揭示了“中场战事”的终局走向。

首先,未来“规模派”和“效率派”必然走向融合。
“规模派”同样意识到单纯堆料的不可持续。Qwen3-Max本身采用先进的MoE(混合专家)架构,就是其主动吸收“效率”技术的明证。未来,巨头们必须将DSA这类稀疏算法和极致的推理优化,作为其旗舰模型的“标配”,否则其“规模”将因成本过高而丧失意义。
而“效率派”也不会永远停留在“性价比”的舒适区。它们必须利用“技术破价”换来的海量市场和数据飞轮,反哺更高性能、更大规模模型的研发。否则,它们也将在“效率”的单一维度上,陷入新一轮的“内卷”。
其次,这场冲突正在倒逼AI产业回归商业本质:从“模型跑分”转向“应用价值”。
当最顶尖的模型和性价比最高的模型同时摆在货架上,客户的选择不再是盲目的“追高”,而是精准的“适配”。市场被清晰地划分:少数高敏、高价值的场景去追逐顶尖模型的极限性能;而海量的、对成本敏感的“长尾应用”,则会拥抱效率模型的极致效率。
这场由“规模”和“效率”共同导演的戏剧性冲突,其真正的价值在于“挤出”了AI的泡沫。它迫使所有玩家——无论是手握万亿参数的巨头,还是掌握效率利器的新贵——都必须回答同一个终极问题:
你所提供的智能,究竟为客户创造了多少可衡量的价值?
在AI的中场战事中,谁能率先回答好这个问题,谁才能定义下半场。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/13367