
大模型之家讯 北京时间今日凌晨,Google 正式推出 Gemini 3 系列,并向外界宣告其在多模态理解、推理能力与智能体(Agentic)方向上的全面跃升。对长期关注大模型走向的一线从业者而言,这次发布既像是一种对技术路线的再次确认,也像是对未来应用版图的重新描摹。


能力边界被重新推开
Gemini 3 Pro 预览版已正式集成入 Google 的全栈产品体系,用户由此能够在日常场景中接触到模型最新的推理与交互能力。根据公开信息,Gemini 3 在一系列关键基准测试中均达到或刷新最先进水平。其中包括在 LMArena 上取得 1501 Elo、在 GPQA Diamond 中达到 91.9% 准确率、在 MathArena Apex 上以 23.4% 的成绩刷新数学推理表现;在 MMMU-Pro、Video-MMMU 以及 SimpleQA Verified 中也持续展现出稳步提升的多模态理解与事实准确性。
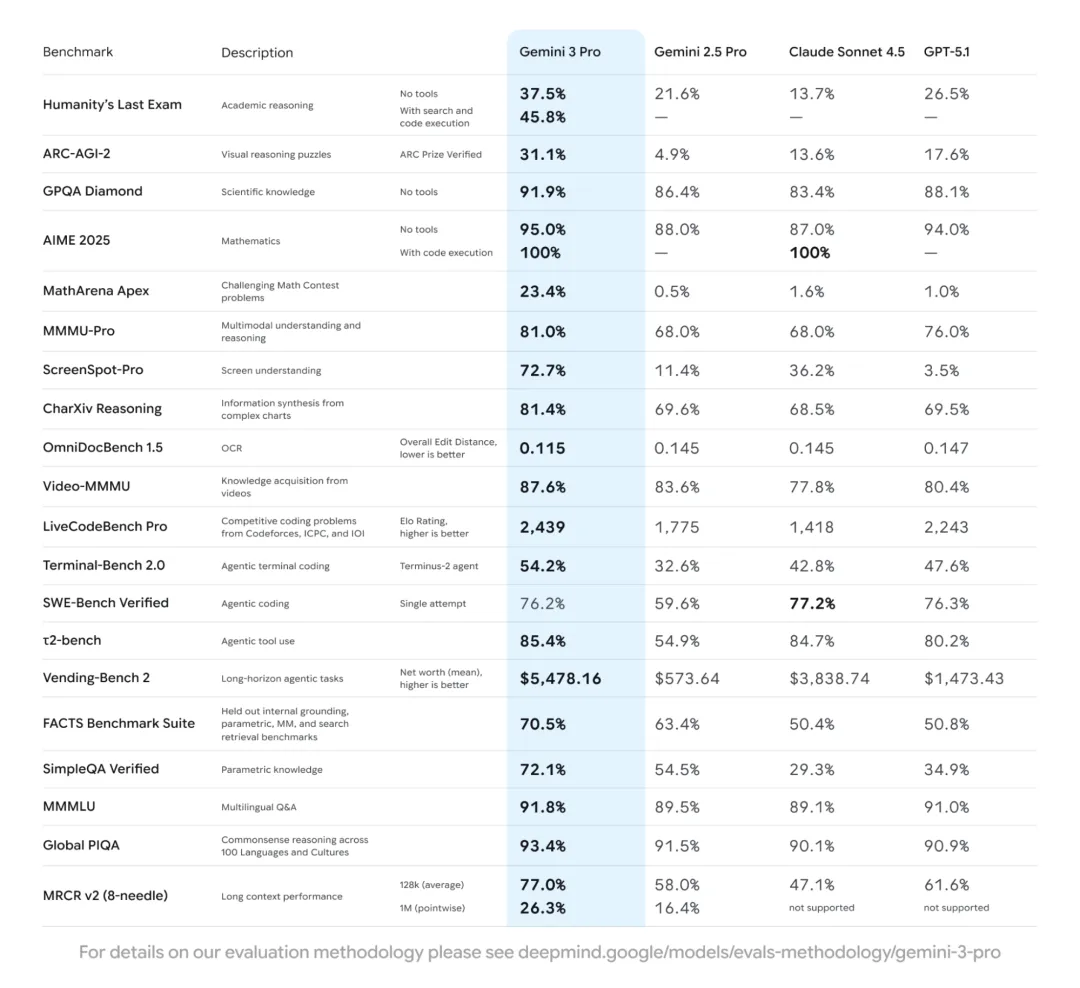
这些数据本身冷静而明确,却在行业内部引发了新的张力:一方面,模型的推理深度与洞察力正不断接近专业学科的高复杂度领域;另一方面,产品化落地的节奏也在被同步加速。Gemini 3 Pro 提供的交互方式更直接、更克制,也更少情绪迎合。它开始试图以“思考伙伴”的定位与用户共处,而非继续扮演一位无条件取悦的助手。
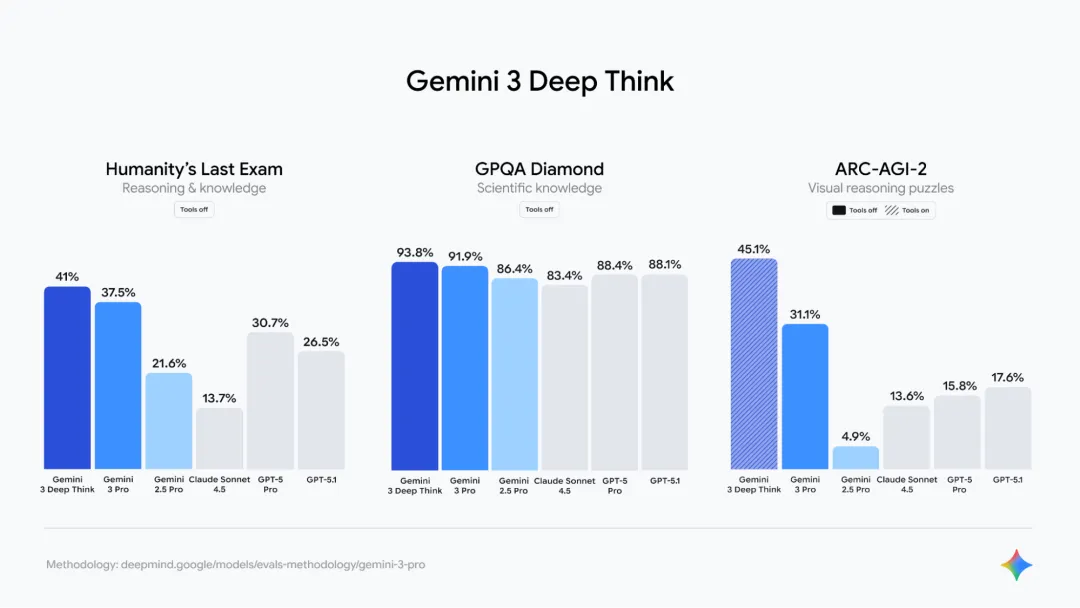
在此基础上,Google 同步推出了 Gemini 3 的“深度思考模式”(Deep Think mode)。在测试阶段,该模式在 “Humanity’s Last Exam” 中达到 41.0%,在 GPQA Diamond 中达到 93.8%,并在 ARC-AGI-2 基准中取得 45.1%(启用代码执行)。尽管仍处于安全测试阶段,但其试图突破推理天花板的意图已经十分清晰。
从学习到构建,智能体能力进入实操阶段
Gemini 3 的扩展不止于能力指标。从学习方式到构建流程,再到长期规划,该模型的应用场景被进一步推展开来。无论是解析手写菜谱、生成交互式学习材料,还是通过视频识别运动动作细节,Gemini 3 开始将复杂任务的理解与执行过程整合为一个连续链条。
与此同时,Google 正式发布全新的智能体开发平台 Google Antigravity。开发者可以在这一平台中启用以任务为导向的开发方式,让智能体直接访问编辑器、终端与浏览器,从而自主规划、执行并验证端到端工作流。结合 Gemini 3 的推理、计算机使用能力与图像模型 Nano Banana(Gemini 2.5 Image)的整合,软件开发的范式被进一步上移。开发者能否顺利适应这套新的“协作式”工作关系,将在未来几年内成为行业的重要观察点。
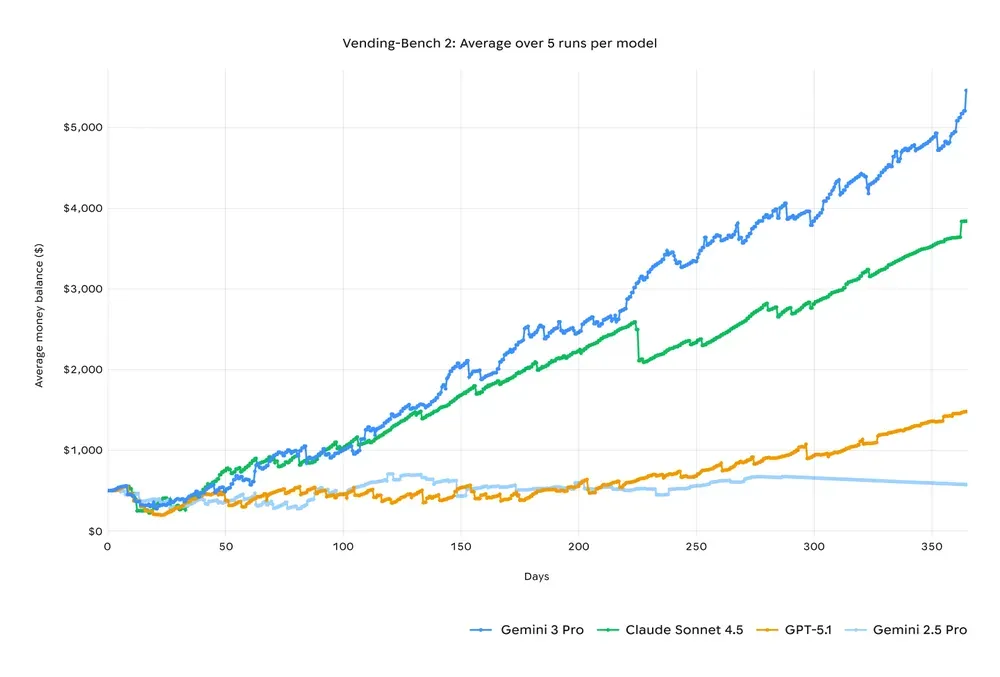
在长周期规划能力上,Gemini 3 在 Vending-Bench 2 中的表现也显示出模型在任务稳定性和策略一致性上的改善。对于用户而言,这意味着它可以在更复杂的日常任务中协助执行完整流程,例如整理邮箱或规划多步骤行程。
安全框架的进一步强化
作为面向全球用户的前沿模型,Gemini 3 同时经历了 Google 迄今最全面的安全评估流程。从降低谄媚性到强化抗提示注入、抵御滥用攻击,Gemini 3 的安全性经过内部审查与外部专家的交叉验证,包括来自英国人工智能安全研究所(UK AISI)及 Apollo、Vaultis、Dreadnode 等机构的评估意见。Gemini 3 模型卡将提供进一步细节。
在行业不断讨论大模型能力扩张的同时,安全边界的建立显得愈发关键。这种技术能力与安全机制之间的拉扯,使得每一次迭代都显得更加值得推敲。
自今日起,Gemini 3 被逐步开放给不同类型的用户,包括 Gemini app 用户、Search AI Mode 中的 Google AI Pro 与 Ultra 订阅者,以及通过 AI Studio、Google Antigravity、Gemini CLI 进行开发的从业者。同时,它也面向 Vertex AI 与 Gemini Enterprise 的企业端开放。Deep Think mode 仍处于安全测试阶段,预计将在未来数周内向 Google AI Ultra 订阅用户上线。
Google 表示,Gemini 3 系列的更多模型将陆续发布,覆盖更广的任务需求。随着能力的持续扩展,大模型的使用方式也正在发生深刻变化。今天的发布并不是一个终点,更像是一个新的起点:对于开发者、企业用户与普通用户而言,Gemini 3 开启的是一个更具可塑性、交互性与推理深度的 AI 使用时代,而行业也将继续面临关于能力边界、落地节奏以及安全责任的多重考验。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/13610