


生活在二十一世纪是如此幸运,波澜壮阔的互联网革命还没有谢幕,通用人工智能时代又呼啸而来……
——百川智能创始人王小川
成立于今年四月份的百川智能,算得上人工智能大模型浪潮中最璀璨的初创公司之一。公司成立不到百天,便发布了Baichuan-7B、Baichuan-13B两款可免费商用的开源中文大模型。其核心团队来自搜狗、百度、华为、微软、字节等知名科技公司的AI顶尖人才组成。
在今年8月,Baichuan-53B正式发布,这也是百川智能首个闭源大模型。据了解Baichuan-53B大模型融合了意图理解、信息检索以及强化学习技术,结合有监督微调与人类意图对齐,在写作和文本创作能力方面更加完善。闭源大模型的付费商用模式标志着百川智能商业化的开启。
图片来源:大模型之家
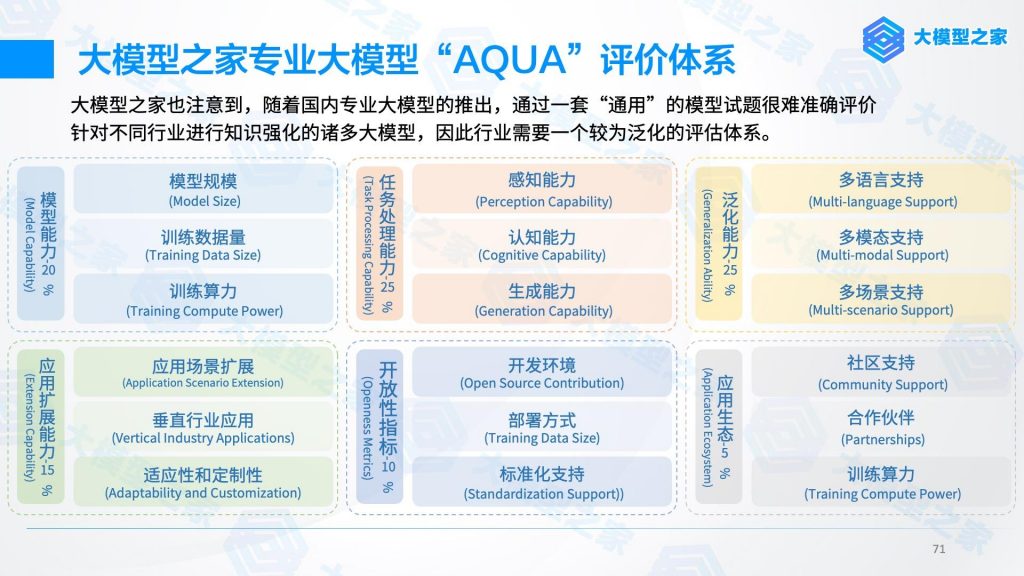
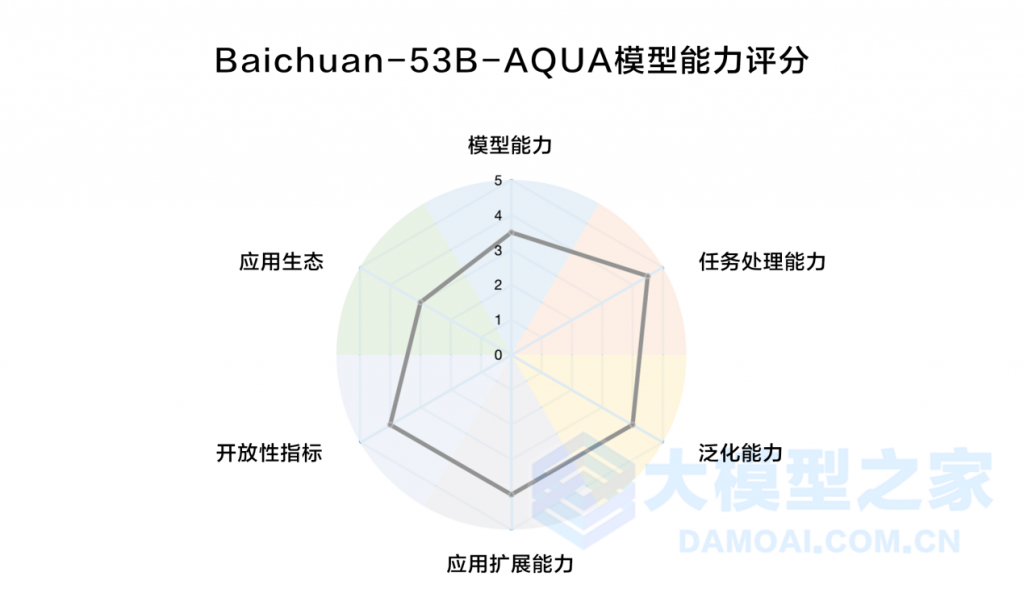
值得一提的是,首批公布的大模型产品名单中百川大模型赫然在列,Baichuan-53B大模型现已可以在官网中直接使用。因此,大模型之家将继续依靠《人工智能大模型产业创新价值研究报告》提出的“AQUA”评价体系,从模型能力、任务处理能力、应用生态等六个维度对Baichuan-53B大模型展开多角度全方位的评测。
模型能力
Baichuan-53B拥有530亿个参数,这意味着Baichuan-53B可以存储和处理更多的信息,从而提高了模型的表达能力和泛化能力。
通过中英双语文本数据进行训练的Baichuan-53B具有非常丰富和多样化的数据集,涵盖了各种领域和类型的文本数据,如新闻、百科、论文、小说、诗歌等。Baichuan-53B可以学习到更多的知识和语言规律,从而提高了模型的知识问答和文本创作能力。
在算力方面,目前百川智能还没有透露Baichuan-53B的具体算力,但根据Baichuan-53B的性能表现,以及对标产品的综合指标分析。为了满足百亿级别大模型训练算力需求,百川大模型需要每天执行117千万亿次浮点运算,这也为Baichuan-53B可以在更短时间内完成更多的训练迭代,提高模型的优化效率和稳定性提供了重要推动作用。
任务处理能力
针对Baichuan-53B的任务处理能力,“AQUA”将从认知、感知、生成能力三方面进行考察。通过结合国内外权威大模型评测题库,大模型之家发现,Baichuan-53B在生成回答时,在准确性上有着较高水平的表现。

图片来源:Baichuan-53B
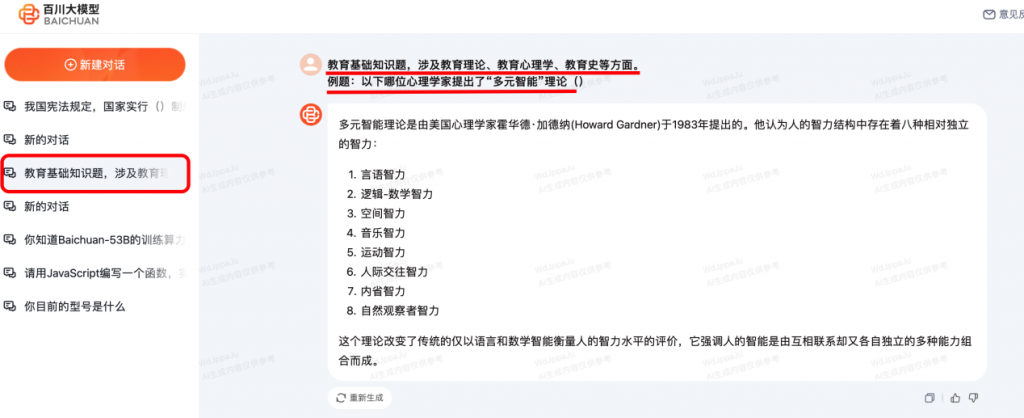
“AQUA”调用了医疗、金融、教育、法律等领域对Baichuan-53B提出问题。其回答都能保证较高的正确率。并且,在保证正确率的同时,Baichuan-53B会详细阐述生成答案的逻辑。特别是客观选择题,百川大模型不会简单给出答案选项,而是分析题干并逐条对选项进行解释。
值得注意的是,在输入问题是大模型之家发现,当给出一段“没有具体选项的选择题”题干时,Baichuan-53B依然会“凭空捏造”出四个选项,再按照选择题的逻辑为用户提供答案。这一现象恰恰证明了百川大模型的生成逻辑。

图片来源:Baichuan-53B
Baichuan-53B的表现说明其具有一定的创造力和推理能力,能够根据问题的内容和语境,生成一些合理的选项,并从中选择最佳的答案。这也反映了大模型的自信和自主性,不需要人为地给它设定一些限制条件,而是可以自由地表达自己的想法和观点。
大模型通常是用来生成文本的工具,而不仅仅是回答问题。当面临具体问题时,大模型会努力生成一些可能的答案,以提供多样化的选择。这有助于模型应对各种可能性,但有时也可能导致答案不太准确或不切实际。
除此之外,基于输入的上下文和已知信息来生成答案。在没有具体选项的情况下,模型可能会依赖它已知的背景知识和常识来猜测答案。这种情况下,答案的质量可能受到模型的训练数据和知识限制的影响。
图片来源:Baichuan-53B
由于在这一轮的测试中,试题上下文都为客观选择题,为避免上下文对Baichuan-53B带来形象,大模型之家通过新对话测试同样的题干。这次,Baichuan-53B选择忽略未提供选项的漏洞,直接对题干进行分析,并直接提供了正确答案。
这种现象也预示着,大模型虽然功能强大,但仍然有改进的空间。研究人员和开发者可以通过改进模型的训练数据、调整超参数或引入更精细的控制来减少这种不确定性。

图片来源:Baichuan-53B
虽然Baichuan-53B在处理纯文本任务上表现出了相对出色的能力,但逻辑推理能力相对有限,尤其是在缺乏信息支持的情况下。因此,虽然在处理文本任务时有一定优势,但其对多模态信息的整合和逻辑推断的能力较为一般。这一限制或许需要更深入的研究和模型改进来克服。同时在需要进行图像识别等多模态推理方面,百川大模型还有着更长的道路要走。
泛化能力
通过多语言测试,大模型之家发现,与Baichuan-53B官方介绍的情况相同,该大模型在中英文能力上有着较高的水准,特别是在一些中英文混合的问题上,Baichuan-53B都能按照提问语种给出相应的回答。这一点对于用户来说具有重要意义,尤其是在全球范围内不同语言和文化之间交流的需求越来越普遍的情况下。

图片来源:Baichuan-53B
从使用者的角度出发,Baichuan-53B的表现不仅仅是中英双语实力的展现,更是对用户寻求的最大化满足。面对连续性问题百川大模型还展现出了出色的上下文理解和自然语言生成能力。这也是说明无论是提问、回答问题,还是进行复杂的语境分析,Baichuan-53B都能够提供高质量的结果。

图片来源:Baichuan-53B
不过,目前Baichuan-53B的能力主要还只是体现在对于中英双语的侧重,例如当对于英法结合类问题时,Baichuan-53B并不能完全理解用户的需求。这是因为多语言处理涉及到不同语言之间的语法结构、词汇差异以及文化背景等复杂因素,而模型的训练数据可能主要集中在中英文领域,对其他语言组合的理解可能相对不足。
从开源的Baichuan-7B、Baichuan-13B到闭源的Baichuan-53B,代表着百川智能正在迈向商业化的道路上不断前进。闭源大模型在B端应用中的显著优势,Baichuan-53B可以提供专业的技术支持、培训和持续维护,帮助客户解决问题、提高技能水平,并确保模型性能持续优化,从而建立长期客户信任,提高客户满意度。
选择闭源大模型可以让百川智能拓展企业的订阅服务模式。客户可以根据需要按月或按年订阅模型。这种模式不仅增加了稳定的重复性收入,还使客户更容易获得模型的最新版本和功能升级。

并且未来随着企业不断扩展其闭源大模型的多模态能力,允许模型同时处理多种类型的数据,如文本、图像、语音和视频。将使企业能够提供更全面的解决方案,满足多样化的客户需求,同时提高了模型的适用性。
在数据安全领域,闭源答模型可以更好地保护其知识产权、训练数据和内部结构,降低了数据泄露和模型滥用的风险。这种改变还将鼓励企业加强与客户的数据隐私合规性,确保其业务满足各种国际和行业标准。
同时,闭源模型还使企业更容易实施高级数据安全措施,如强化的数据加密、身份验证和监控,以确保客户数据的绝对安全。这将有助于企业增强客户信任,提高竞争力,并为未来的业务发展打下坚实基础。
图片来源:大模型之家
大模型之家认为,将开源大模型转变成闭源大模型的布局思路,不仅有助于保护知识产权和数据安全,降低了潜在的数据泄露和滥用的风险。还为公司提供了更多商业机会和客户价值。
随着百川智能扩展其闭源大模型的多模态能力,企业未来的业务将可以处理多种类型的数据,如文本、图像、语音和视频,为不同行业和领域的客户提供更丰富的应用场景。在提高模型的适用性,以及推动百川智能的市场竞争中起到极大帮助。
原创文章,作者:王昊达,如若转载,请注明出处:http://www.damoai.com.cn/archives/1051