
大模型之家讯 8月4日,小米公司正式开源声音理解大模型MiDashengLM-7B,其在22个公开评测集上刷新多模态大模型性能纪录(SOTA),单样本推理首Token延迟(TTFT)仅为业界先进模型的四分之一,同等显存下的数据吞吐效率更是达到同类模型的20倍以上。这一突破性成果标志着小米在音频理解领域的技术积累已进入新阶段,为全场景智能生态构建关键支点。
技术突破:全局语义刻画重构声音理解边界


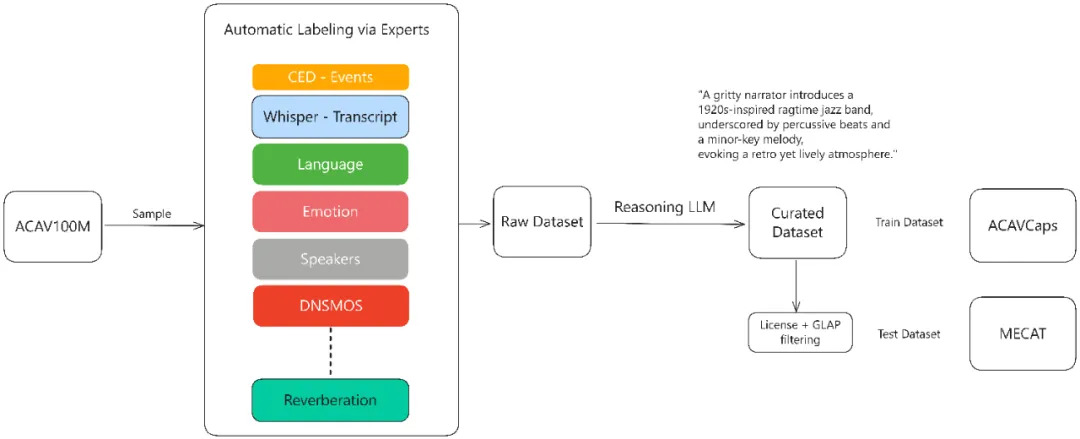
MiDashengLM-7B的核心在于其创新的训练范式。模型采用Xiaomi Dasheng音频编码器与Qwen2.5-Omni-7B自回归解码器的融合架构,通过通用音频描述对齐策略,实现对语音、环境声音与音乐的统一理解。与传统依赖ASR转录的碎片化处理不同,该范式避免了环境声与音乐信息的丢失——基于ASR的方法在ACAV100M-Speech数据集上会损失90%的潜在有用数据。训练数据经多专家分析管道生成:原始音频经Dasheng-CED模型预测2秒粒度声音事件,再由DeepSeek-R1合成统一描述,最终形成ACAVCaps数据集。这一流程使模型能捕捉说话人情感、空间混响等深层声学特征,在音频描述任务(FENSE指标)、声音理解(FMA/VoxCeleb-Gender等)及音频问答任务中全面超越Qwen与Kimi同类7B模型。
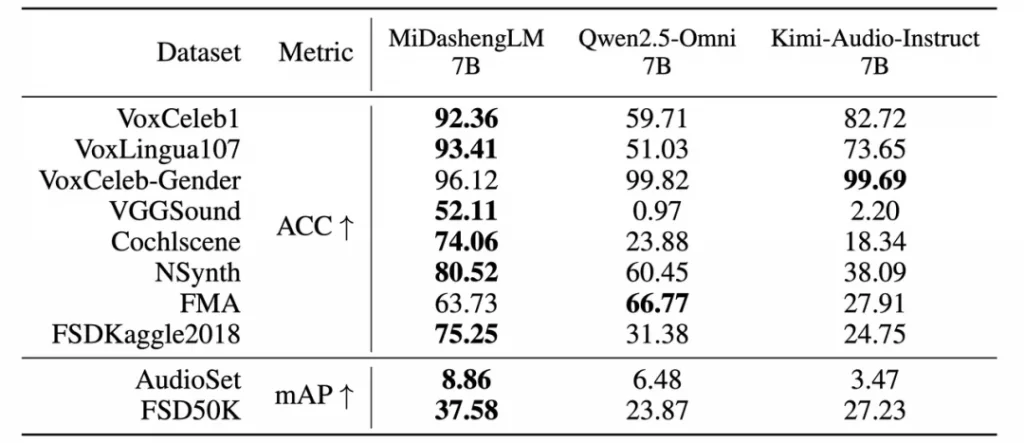
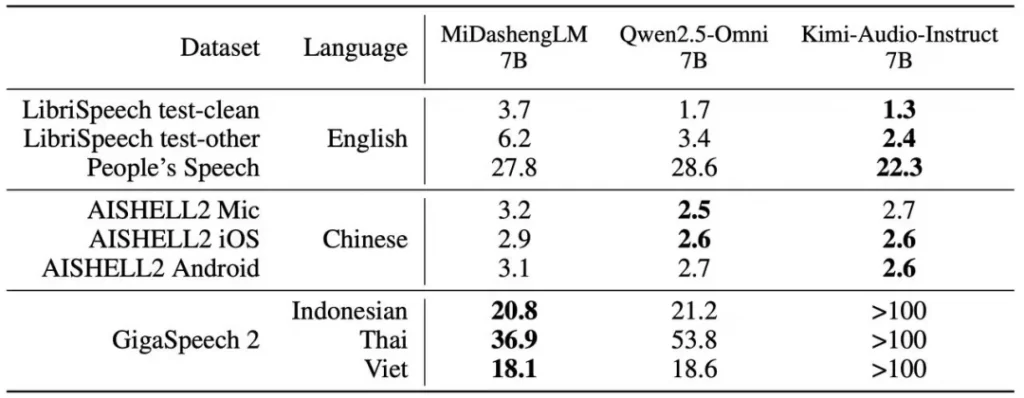
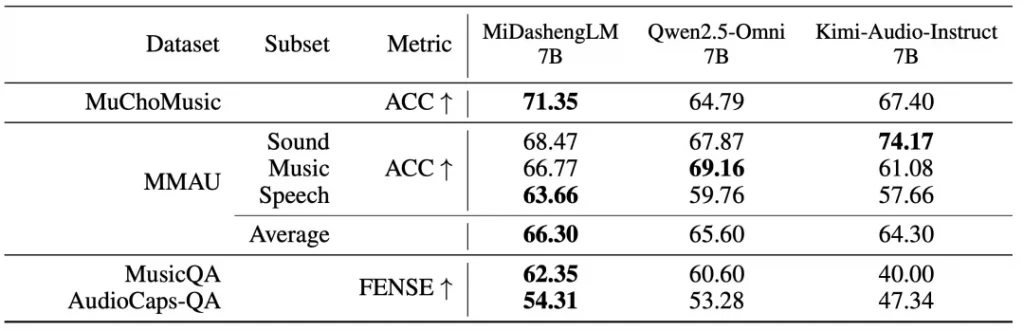
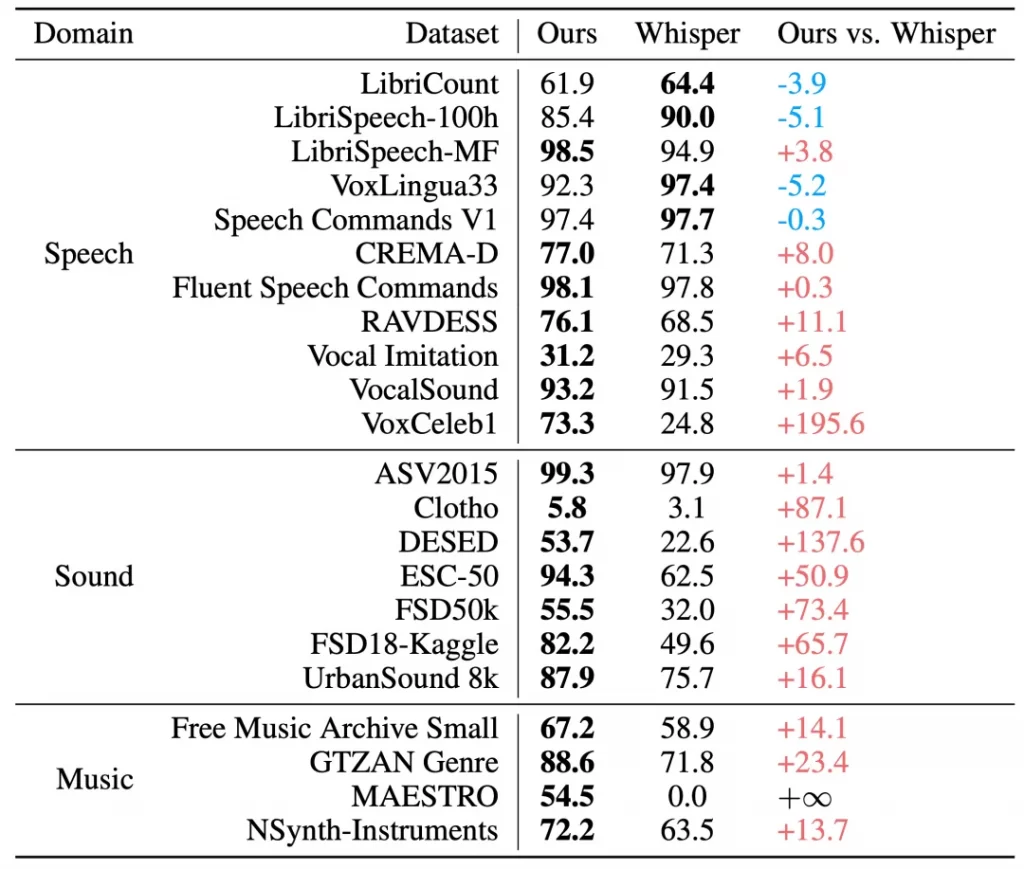
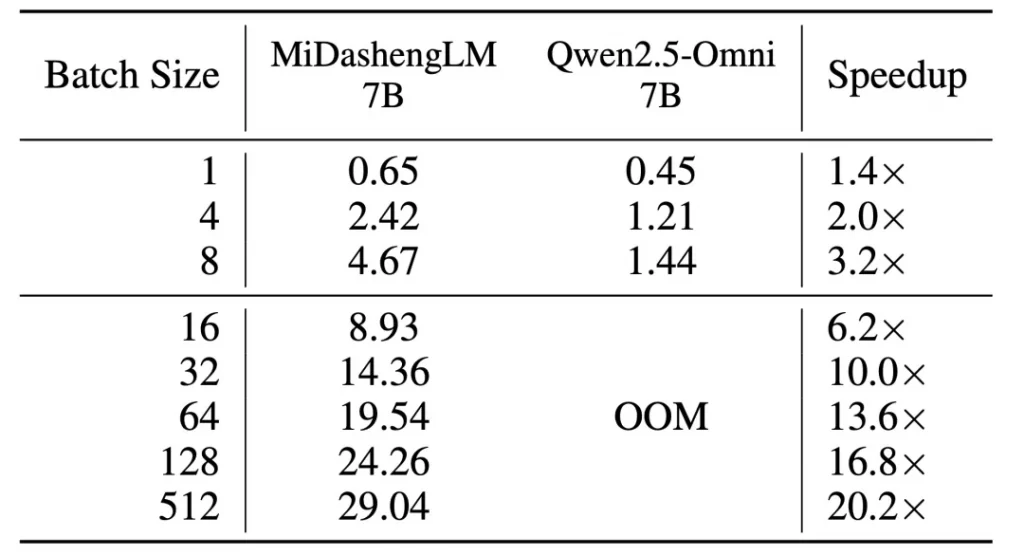
效率革新:计算架构优化释放百倍并发潜能
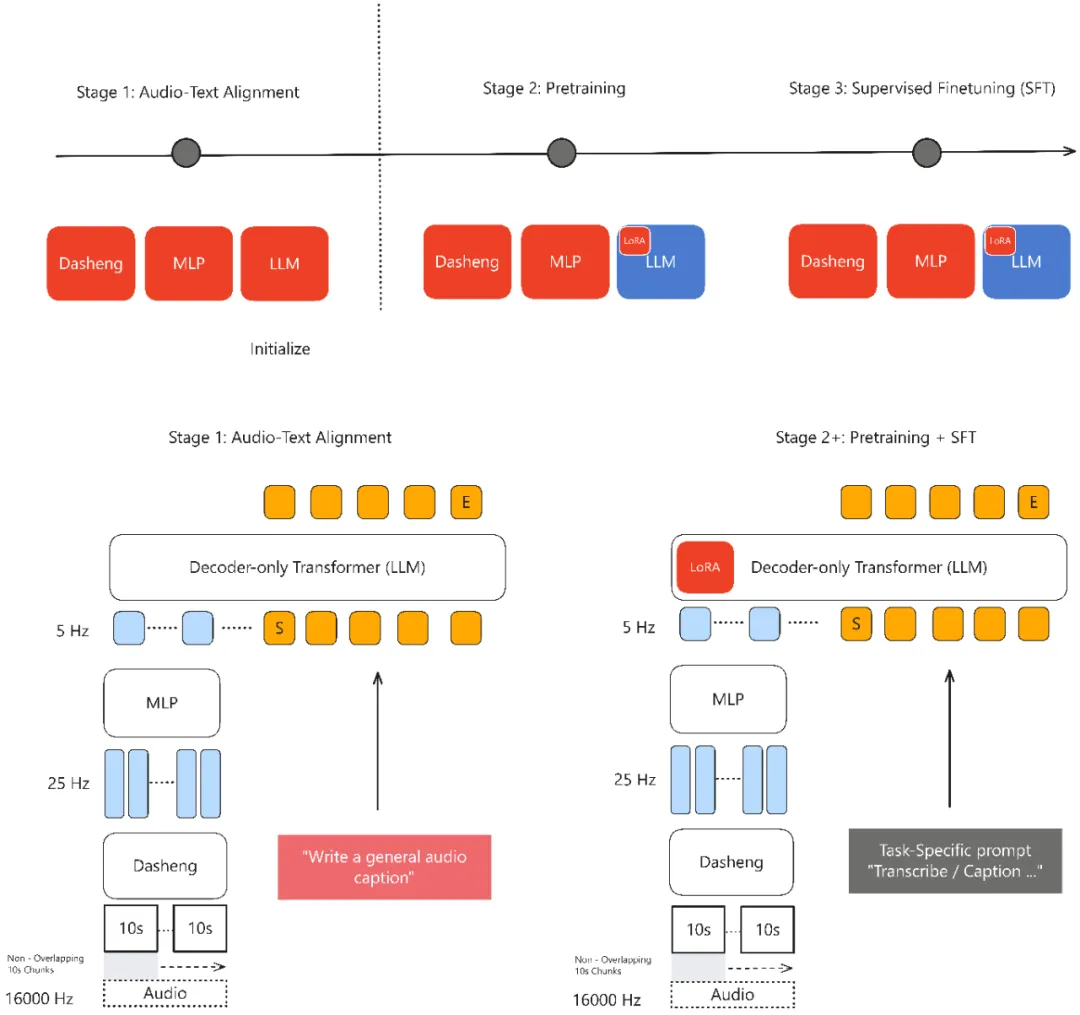
推理效率的跃升是MiDashengLM-7B的另一核心竞争力。在单样本推理场景下,其TTFT仅需业界模型的四分之一;当处理30秒音频并生成100个token时,80GB显存环境下MiDashengLM-7B可支持512的batch size,而Qwen2.5-Omni-7B在batch size达16即触发显存溢出(OOM)。这源于Xiaomi Dasheng架构的深度优化:音频编码器输出帧率从25Hz降至5Hz,降幅达80%,在维持核心性能的前提下显著降低计算负载。实际部署中,该模型可在同等硬件条件下支持更高并发请求,大幅降低企业级应用的计算成本,为智能家居、汽车座舱等实时交互场景提供技术支撑。
开源透明:全栈开放推动行业标准演进
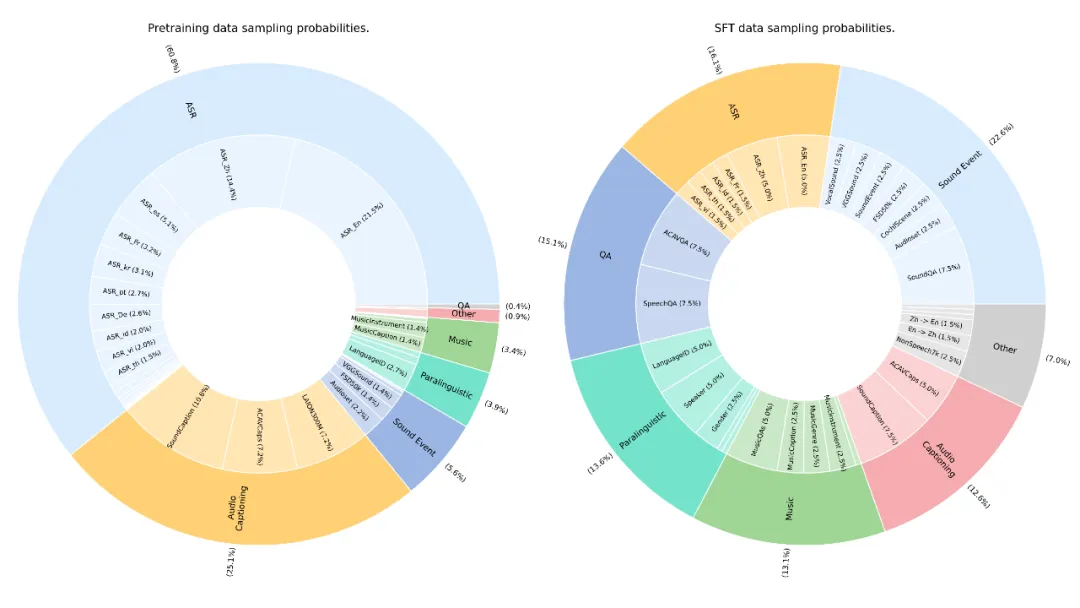
小米此次开源彰显技术开放姿态。MiDashengLM训练数据100%源自公开资源,涵盖语音识别、环境声音、音乐理解等五类110万小时数据,完整公开77个数据源配比及技术报告。Xiaomi Dasheng系列模型已在小米智能家居、汽车座舱等30余场景落地应用,此次开源进一步强化了其作为声音基座模型的行业价值。值得注意的是,ACAVCaps数据集将在ICASSP 2026论文评审后开放,MECAT Benchmark已率先开源,为行业提供标准化评估基准。
小米此次升级不仅填补了音频理解在跨领域能力的空白,更通过“全局语义刻画”范式重构了声音理解的技术路径。当行业仍在纠结语音转录的精确度时,MiDashengLM已将目光投向环境声与音乐的深层关联——它不仅能听懂“发生了什么”,更能解析“为何发生”。随着小米加速推进Xiaomi Dasheng系列模型的终端离线部署,这场从碎片化转录到全局语义的范式革命,或将重新定义人机交互中“听”的边界,让智能设备真正拥有“听懂世界”的能力。在AI多模态竞争白热化的当下,小米以开源姿态切入音频理解这一关键拼图,正悄然改写全场景智能生态的叙事逻辑。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/11954