
大模型之家讯 今日,在阿里云栖大会上,阿里云集中发布六款大模型新品及一个全新语音品牌,涵盖文本、视觉、语音、视频、代码与图像等核心场景,展现其在大模型全栈能力上的最新进展。
此次发布的产品包括:参数规模超万亿的旗舰模型 Qwen MAX、新一代全模态模型 Qwen3-Omni、视觉理解模型 Qwen3-VL、图像编辑模型 Qwen-Image、代码大模型 Qwen3-Coder、视频生成模型 Wan2.5-Preview,以及企业级语音基座大模型品牌 通义百聆。
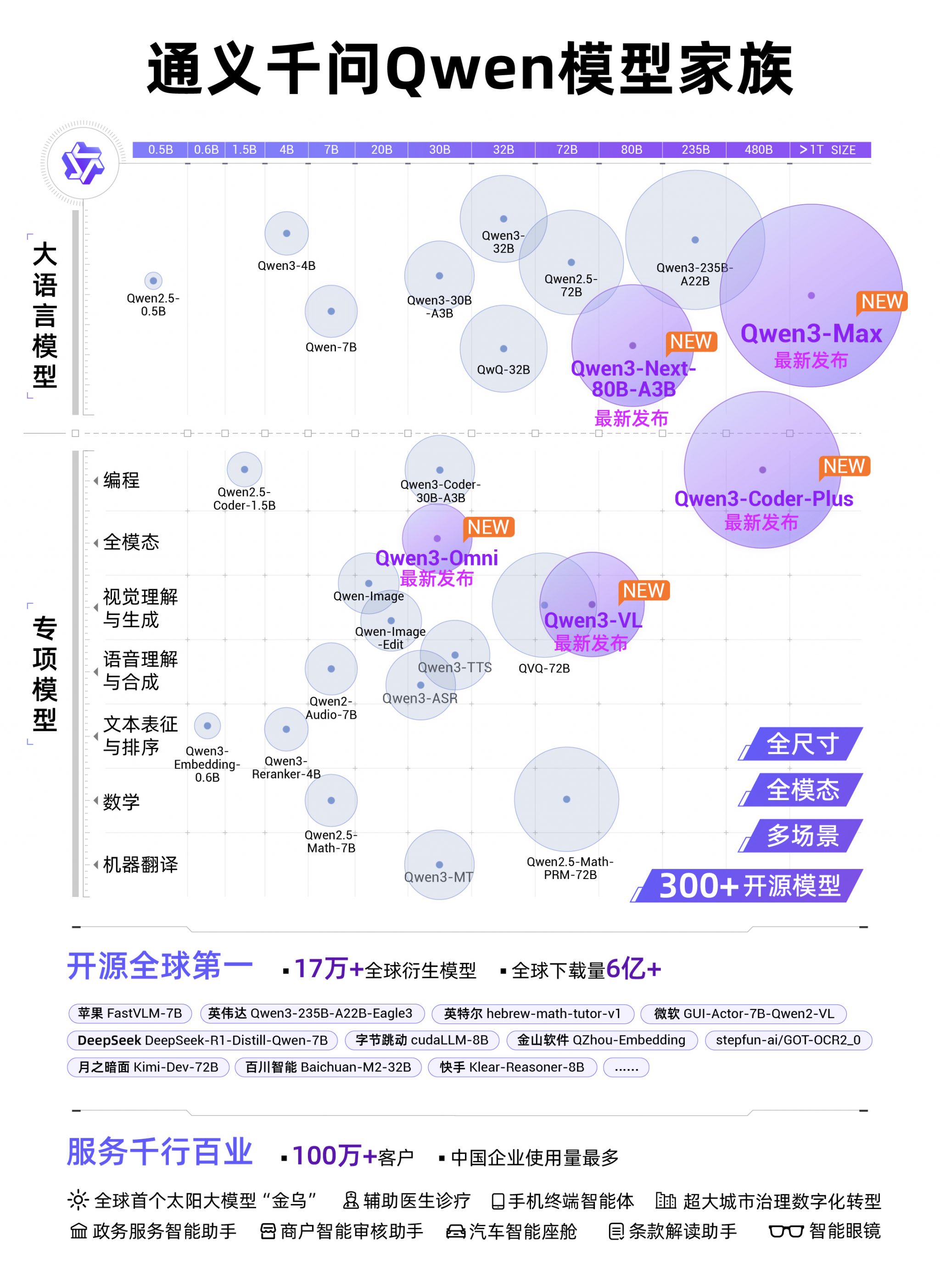

参数规模与基准成绩:Qwen MAX
Qwen MAX 作为参数规模超万亿的旗舰模型,在代码生成、工具调用和数理推理任务中取得了多项国际基准成绩。例如,在 SWE-Bench Verified 评测中得分 69.6,在 AIME25 数学推理测试中获得满分 100 分,展现出相较此前开源版本显著提升的综合能力。
多模态与语音交互:Qwen3-Omni
Qwen3-Omni 定位为新一代全模态大模型,支持 19 种语言及方言输入、10 种语言输出,可处理长达 30 分钟的音频内容,并基于 Thinker-Talker MoE 架构实现跨模态处理。该模型原生支持 Function Call 与 MCP 协议,可应用于车机、智能音箱等交互场景。在 VoiceBench-CommonEval 等评测中,其语音理解与生成能力已超过多个开源与闭源对比模型。
视觉与长上下文:Qwen3-VL
Qwen3-VL 在视觉理解方向进一步强化,可对长达两小时的视频进行精确定位,并支持最高扩展至 100 万 token 的上下文处理。模型能力涵盖视觉智能体操作、可视化编程、3D 空间感知、复杂文档解析等,适配机器人、安防和多模态研究等场景。OCR 识别能力扩展至 32 种语言,提升了在复杂光照和文本场景下的稳定性。
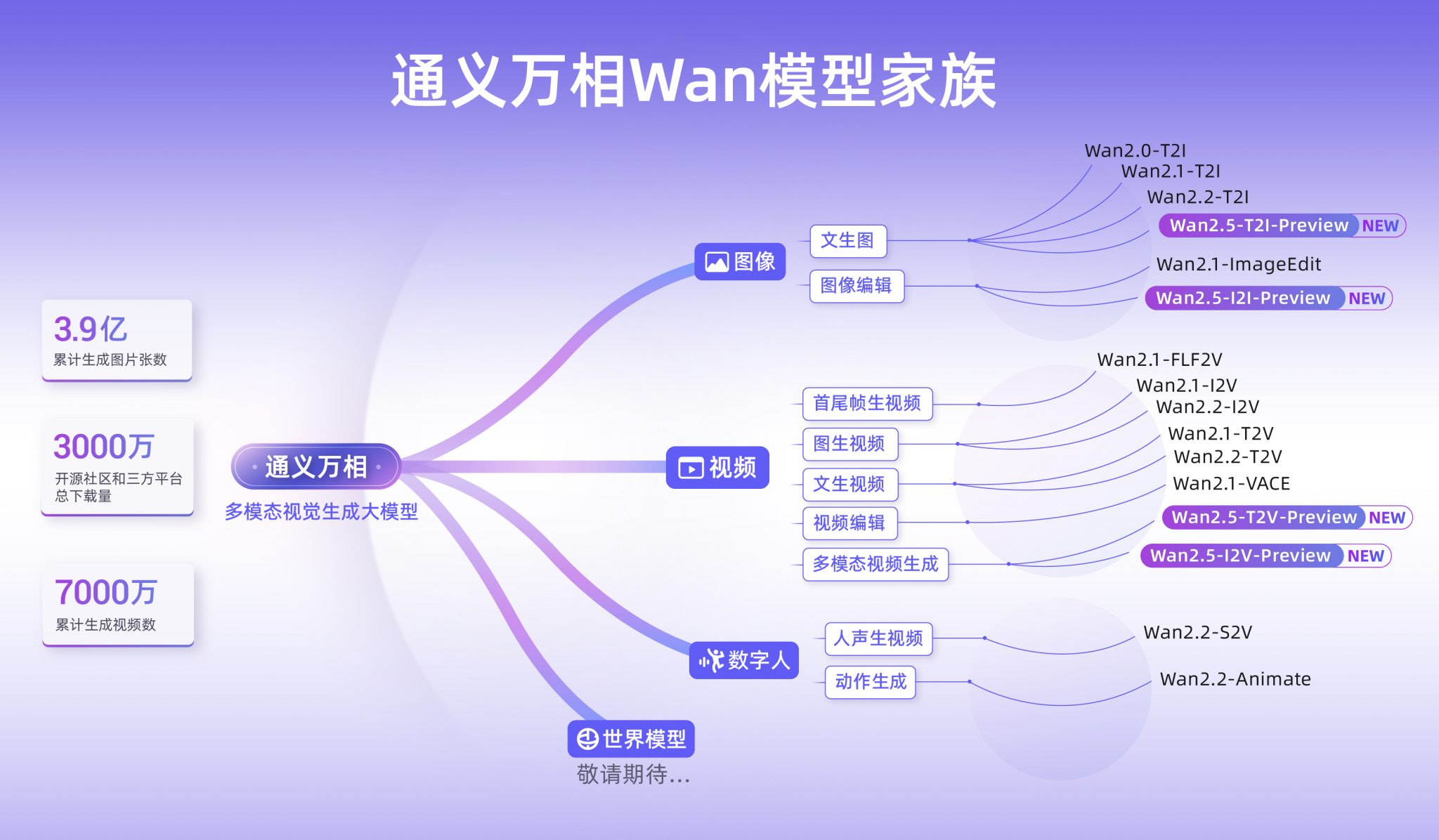
图像、代码与视频生成:Qwen-Image、Qwen3-Coder、Wan2.5-Preview
图像编辑模型 Qwen-Image-Edit-2509 支持多图参考编辑与 ControlNet 集成,提升了人脸、商品与文字一致性,适用于电商、广告等场景。
Qwen3-Coder 通过 256K 上下文支持实现项目级代码修复,在 TerminalBench 等评测中显著提升,强调安全性与多模态输入能力。
Wan2.5-Preview 首次实现音画同步的视频生成,支持最长 10 秒、1080P 的多模态创作,同时在图像生成与编辑方面加强了结构化图表生成与一致性处理。
企业语音应用:通义百聆
通义实验室还发布了全新语音大模型品牌“通义百聆”。该模型整合 Fun-ASR 与 Fun-CosyVoice 两项技术,针对语音识别“幻觉输出”“串语种”“热词失效”等行业难点提出了解决方案。通过 Context 增强架构,幻觉率从 78.5% 降至 10.7%,并支持跨语种语音克隆与行业术语的定制化识别。
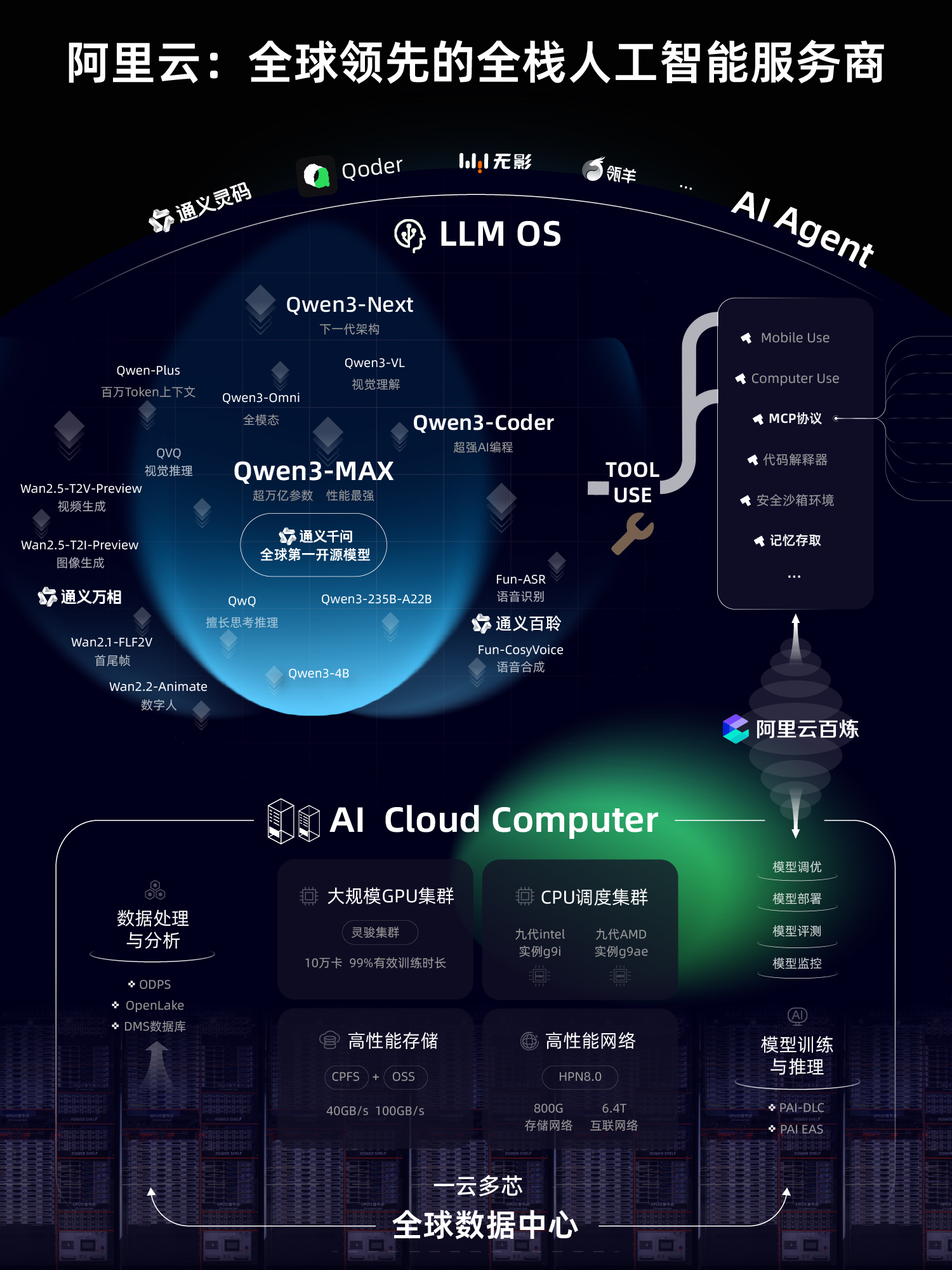
开放与使用方式
目前,上述模型已同步上线,用户可通过魔搭、GitHub、Hugging Face 搜索部署,或在阿里云百炼平台调用 API。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/13074