
大模型之家讯 北京时间9月25日,Meta FAIR(Fundamental AI Research)团队宣布推出一款全新研究模型——CWM(Code World Model)。这是一个专为代码生成与推理设计的语言模型,参数规模32B,上下文长度可达131k tokens。值得注意的是,这是业界首次在代码生成中系统性引入“世界模型”(World Model)的概念。
与现有代码大模型相比,CWM的核心差异在于其并不仅停留在文本生成层面,而是能够在生成过程中模拟代码的执行逻辑。换句话说,它可以在内部追踪变量状态和环境反馈,帮助模型更好地理解代码执行过程,从而提升调试、修复和规划的能力。Meta方面认为,这使CWM更接近人类程序员的思维方式。
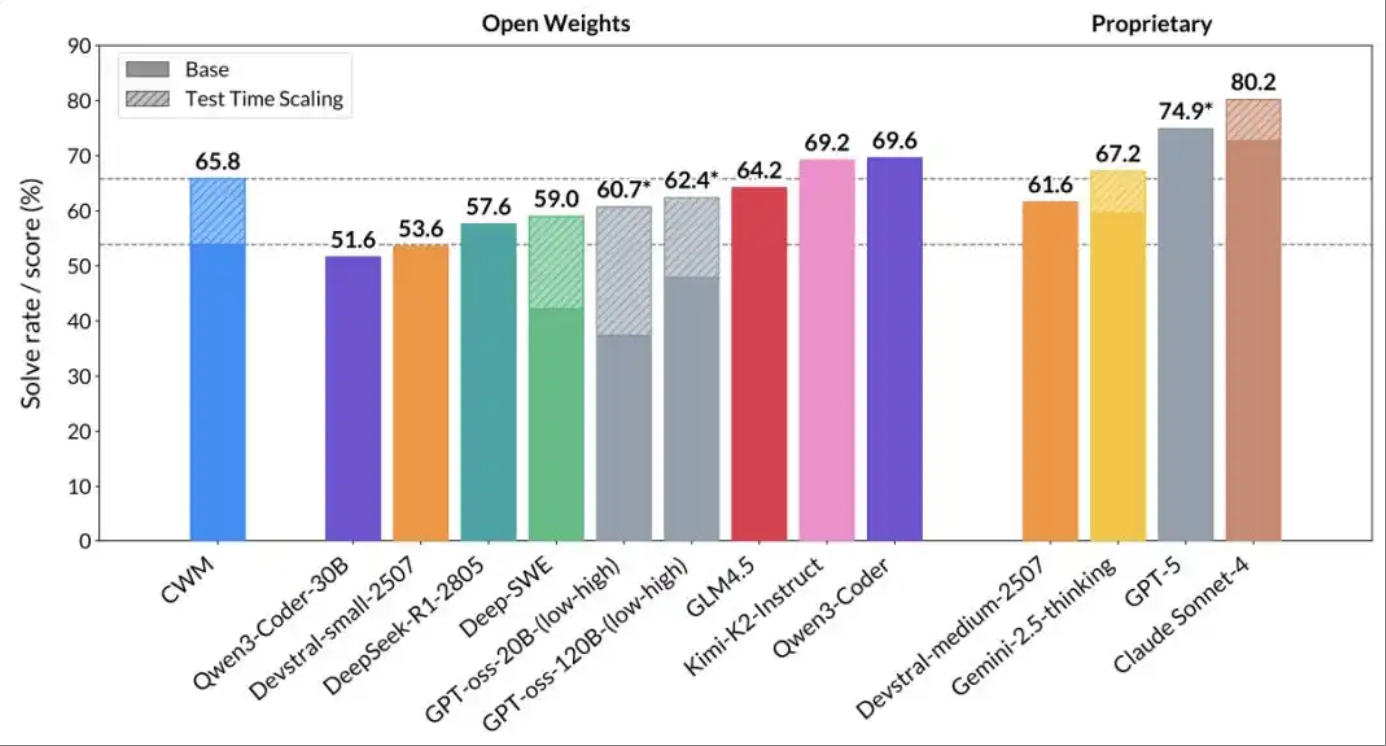

在公开测试中,CWM在多个代码与推理任务上表现突出。例如,在软件工程任务基准SWE-bench Verified中取得65.8%的成绩,超越所有同规模开源模型,接近GPT-4水平。在编程竞赛与数学任务(如Math-500和AIME模拟题)中也展现了较强的推理与生成能力。
Meta此次选择了开放路线,公布了模型架构、训练细节及多个阶段的权重检查点。模型以64层decoder-only Transformer为基础,采用局部与全局交替的Attention机制,以平衡长上下文输入下的效率与覆盖范围。FAIR团队提供了包括预训练模型、监督微调版本(SFT)和强化学习扩展版本在内的三个checkpoint,面向研究人员开放。
在训练方法上,CWM分为三个阶段:首先通过8T tokens数据完成通用语言与代码预训练;随后引入5T tokens的“世界建模”数据,模拟代码执行轨迹与真实交互过程;最后再进行大规模的监督微调和多任务强化学习。训练过程采用了FlashAttention-3与fp8低精度加速,并在安全性方面遵循了Frontier AI Framework。Meta方面强调,CWM不会在网络安全、化学或生物等敏感领域构成滥用风险。
不过,目前CWM的世界建模数据仅覆盖Python语言,尚未扩展至C++、Java等主流语言,这意味着其跨语言应用仍有待进一步研究。此外,该模型未经过RLHF(Reinforcement Learning from Human Feedback)环节,因此并不适合作为对话型Chatbot使用。Meta方面也明确指出,CWM定位于“研究用途”,仅供非商业研究开放。
Meta FAIR研究科学家Gabriel Synnaeve在介绍中表示,这一成果验证了“代码世界建模”对提升推理与代码生成的价值。他同时强调,CWM的研发是团队协作的结果,未来研究方向包括多语言扩展与更复杂场景下的自动化编程助手探索。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/13084