


当”跑分”不再能定义一切,AI产业的目光齐刷刷转向一个更残酷的维度——”你能独自干多久的活”?
2026年5月,大模型行业的竞争标尺被彻底改写,一场由”极致性价比”驱动的智能体普惠浪潮全面铺开。当模型定价从”按分计价”逼近”按厘计价”,AI应用的规模化临界点正在被提前引爆。
在大模型之家《2026年5月大模型热力榜》中,我们共收录了568个大模型及其所属企业。本月最显著的变化,是”智能体能力”取代”综合跑分”成为榜单权重最高的评价维度:多款模型在真实工程任务中展示了从编译器开发到桌面应用构建的端到端交付能力,8小时级甚至35小时级的持续自主工作已成为旗舰模型的标配。”模型开源+芯片适配+API降价”的三重共振,正在将中国AI产业从”参数内卷”推向”生态协同”的新竞合阶段。
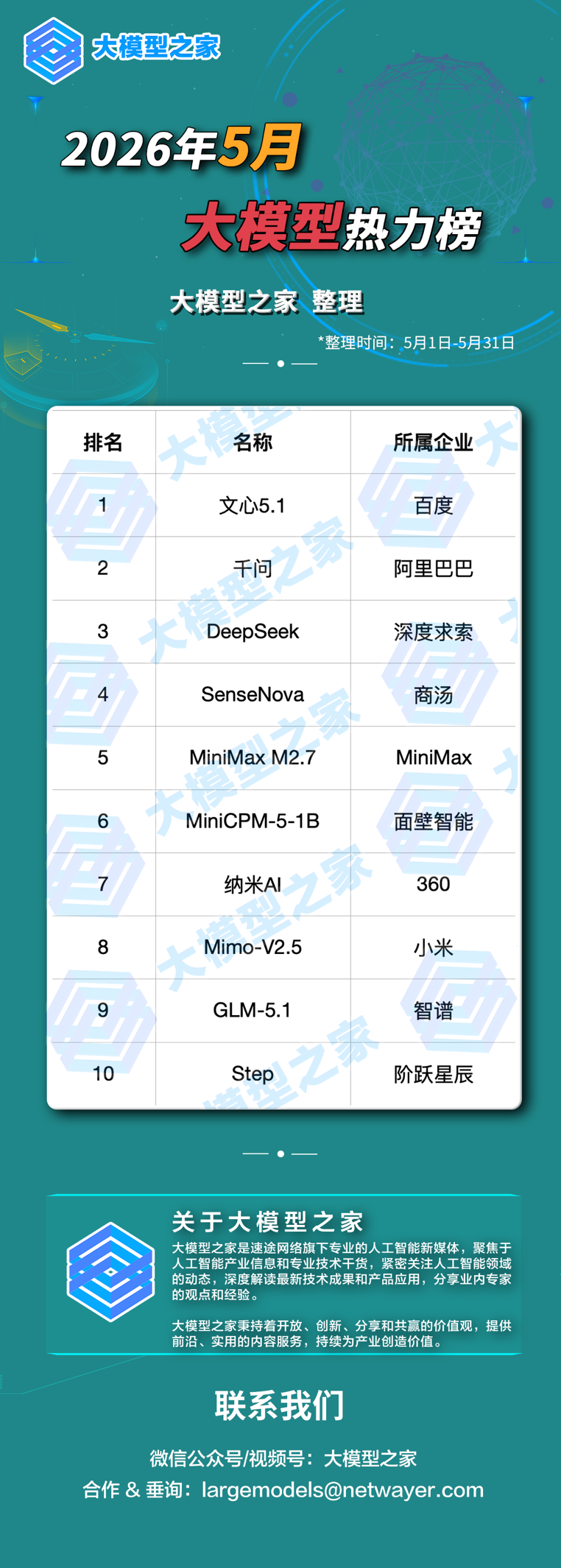
百度:文心5.1发布+Create大会智能体全栈出击
5月9日,百度发布文心大模型5.1,采用”多维弹性预训练”技术,总参数压缩至文心5.0的约1/3、激活参数压缩至约1/2,预训练成本仅为业界同规模模型的6%。该模型在LMArena搜索榜以1223分居国内第一、全球第四,Agent能力超越DeepSeek-V4-Pro,创意写作接近Gemini 3.1 Pro,AIME26数学竞赛得分99.6。5月13-14日Create2026大会上,李彦宏提出AI时代新度量衡DAA(日活智能体数),发布通用智能体DuMate(百度搭子)、代码智能体秒哒3.0(90%代码由自身生成)、数字人智能体百度一镜、自我演化决策智能体伐谋2.0(登顶MLE-Bench)。百度智能云全面升级为面向大规模智能体应用的新全栈AI云,发布30余项新能力,推出全模态训练框架LoongForge(训练效率领先行业一倍并开源)。昆仑芯天池256卡超节点已点亮,将于6月上市。此外,百度智能云发布AI营销应用Hogee、视觉智能体平台百度一见、AI养老解决方案福宝等。
阿里巴巴:Qwen3.7-Max登顶国产第一+真武M890芯片发布
5月20日阿里云峰会上,阿里巴巴发布全新一代千问旗舰模型Qwen3.7-Max,在三方机构Arena全球大模型盲测总榜中位列国产模型第一,超过Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1,性能接近GPT、Claude、Gemini最强模型。该模型面向智能体全新设计,在编程(SWE-Pro、Terminal Bench 2.0领先)、推理(GPQA Diamond 92.4分超越Opus-4.6)、通用智能体(MCP-Atlas、MCP-Mark创国产新高)等核心能力上实现突破。最引人注目的是其长程自主执行能力:在平头哥真武M890芯片上,模型从零自主工作35小时,完成1158次工具调用,将推理内核性能提升10倍。同期,阿里发布平头哥新一代训推一体AI芯片真武M890(144GB显存,性能为上代3倍),以及基于该芯片的磐久AL128超节点服务器(128卡组成一台计算机)。阿里云宣布百炼平台全面开放,与月之暗面、MiniMax、智谱、阶跃星辰等达成合作。阿里AI业务ARR已超80亿元,预计年底突破300亿元。
DeepSeek:V4永久降价75%+登顶全球调用榜+多模态技术公布
DeepSeek在4月24日发布V4系列预览版后,5月持续引爆市场。5月23日,DeepSeek宣布V4-Pro永久降价75%,将原本限时折扣改为永久定价。5月25日,DeepSeek-V4-Flash登顶OpenRouter全球调用榜,为DeepSeek系列史上首次。V4系列采用创新CSA/HCA混合注意力架构,V4-Pro为1.6T参数/49B激活,V4-Flash为284B参数/13B激活,均支持1M上下文,以MIT协议全面开源。在性能方面,V4-Pro在SWE-bench Verified编码代理任务取得80.6%,Agent编码能力首次超越Claude Sonnet 4.5,接近Opus 4.6非思考模式。5月30日,DeepSeek发布多模态技术”Thinking with Visual Primitives”(以视觉原语思考),以V4-Flash为语言主干,自研ViT视觉编码器,支持任意分辨率输入。此外,V4系列已原生适配华为昇腾950PR等国产芯片,推理效率提升3倍以上。DeepSeek正与腾讯和阿里巴巴就首轮融资进行洽谈。
商汤科技:日日新6.7 Flash-Lite发布+U1开源获10家国产芯片适配
5月8日,商汤发布日日新SenseNova 6.7 Flash-Lite轻量化多模态智能体模型,专为真实办公工作流设计,Token消耗直降60%,同步开放SenseNova Token Plan和GitHub开源SenseNova-Skills办公技能套件。4月28日发布并于5月持续发酵的SenseNova U1系列原生理解生成统一模型,基于NEO-unify架构彻底摒弃视觉编码器和VAE,首次实现连续性图文创作输出,8B-MoT版本在MMMU达74.78、MathVista达84.20,超越同量级模型。U1系列开源后,壁仞科技、寒武纪、昆仑芯、摩尔线程等10家国产芯片完成Day 0适配。5月12日,商汤研究团队在arXiv发布SenseNova-U1论文(编号2605.12500),展示VLA和世界模型方向的初步成果。5月18日,商汤推出新一代智能体模型,机器人小店SenseMartGo落地上海。2025年财报显示,生成式AI收入36.29亿元同比增长51%,占总营收72.4%。股价较历史低点涨超200%。
MiniMax:M3发布+Mavis多Agent系统+企业客户破百万
5月31日,MiniMax正式发布M3模型,这是国内首个齐备前沿编程能力、1M超长上下文、原生多模态三大要素的模型,也是目前唯一的开源模型。M3采用全新MSA(MiniMax Sparse Attention)稀疏注意力架构,在SWE-Bench Pro上超过GPT-5.5和Gemini 3.1 Pro,接近Opus 4.7,在多模态测试集OmniDocBench上超过Gemini 3.1 Pro。伴随M3发布,MiniMax Code同步更新,并推出Token Plan套餐(Plus/Max/Ultra三档)。5月28日,MiniMax推出Mavis(MiniMax as a Jarvis)多Agent桌面重大更新,支持微信/飞书接入、上下文隔离、Team Engine编排,解决”上下文焦虑”问题。同日,Token Plan和Agent Plan合并为统一套餐。截至5月28日,MiniMax全球企业开发者客户超百万(半年增长5倍),全球用户规模约3亿,ARR翻番周期压缩至60天。此前5月发布的M1推理模型(全球首个开源大规模混合架构推理模型)已验证了其在长上下文和Agent工具使用方面的全球领先能力。
面壁智能:端侧大模型开源周五项连发,定义端侧AI终局
5月25日至29日,面壁智能联合OpenBMB举办”端侧大模型开源周”,每日发布一项核心技术成果,实现从模型到框架到数据的全栈开源。Day 1(25日):BitCPM-CANN——国内首个完全基于华为昇腾的三值(1.58-bit)大模型,含0.5B/1B/3B/8B四个尺寸,推理阶段释放约6倍显存,能力保留率90%-97.2%,未来有望在手机上运行60B大模型。Day 2(26日):MiniCPM5-1B——1B参数实现2B级性能,在AA榜单位列2B以下规模Top 1,FP16仅占约2GB内存,INT4量化下压缩至0.5GB。Day 3(27日):ForgeTrain——全球首个完全由AI编写、零人类代码介入的生产级大模型训练框架,在H100上比英伟达Megatron快10%,在昇腾上比MindSpeed快10%。Day 4(28日):PilotDeck——智能体操作系统。Day 5(29日):UltraData系列数据集——Ultra-FineWeb-L3(600B Tokens,中文200B+,全球最大中文预训练合成数据集)和UltraData-SFT-2605(国内首个千万级含深思考/非思考标注的SFT数据集)。
360集团:安全龙虾+龙虾教练+智能体安全报告
5月11日,360启动”龙虾计划”,向全体员工发放每人1亿Token,推动从”使用AI工具”到”带着AI团队工作”的演进。5月13日,新一代360安全龙虾正式发布,定位为运行在安全底座上的”AI专家团操作系统”,在PC、Mac、安卓、iOS全终端上线。同期推出的”龙虾教练”功能,支持用户在10分钟内用自然语言训练专属智能体(涵盖角色定义、能力配置、工作流编排)。在成本控制上,其独创的高缓存命中率技术使Token消耗相比海外同类产品节省60%-98%。安全方面,每只”专家虾”在云端完全隔离的沙箱中运行,实时行为监测。5月25日,360 AI安全研究院发布《智能体安全新范式》报告,提出”智能体安全六层攻击面模型”,指出Skill正在成为智能体生态的重要风险入口。此外,360纳米AI平台已汇聚超5万个智能体,支持”多智能体蜂群”协同。360智脑通用大模型在天津完成备案,在天津港等场景投入实际应用。360人工智能研究院两项成果入选ICML 2026。
小米:MiMo-V2.5系列开源+API永久降价+首代机器人VLA模型
4月23日公测、4月28日开源、5月持续发酵的MiMo-V2.5系列是小米迄今最强模型。MiMo-V2.5-Pro拥有1.02T参数/42B激活,采用混合注意力架构(局部窗口+全局注意力6:1交错),支持1M上下文,KV缓存缩减近7倍。在Artificial Analysis榜单上,综合智能指数和Agent指数均位列全球开源模型并列第一,在GDPVal-AA、Claw-Eval等多项测评中超越DeepSeek-V4-Pro和Kimi K2.6。实战方面,模型4.3小时(672次工具调用)从零完成SysY编译器(隐藏测试满分233/233),11.5小时完成8192行代码的桌面视频编辑器。开源首日适配平头哥、亚马逊云科技、AMD、昆仑芯、燧原、沐曦、天数智芯等多家芯片。5月27日,小米宣布API永久降价,最高降幅达99%。同期,小米发布首代机器人VLA大模型Xiaomi-Robotics-0(4.7B参数,80ms推理延迟,30Hz控制频率),在LIBERO、CALVIN等仿真基准全面刷新SOTA。小米2026年Q1财报显示研发投入90亿元,同比增长33.4%,今年AI投入至少160亿元。
智谱:GLM-5.1持续发酵+5V-Turbo多模态+高速版API 400 tokens/s
4月发布的GLM-5.1在5月持续引发关注。作为全球唯一达到8小时级持续工作的开源模型,GLM-5.1在SWE-Bench Pro上以58.4分排名全球第一,超越GPT-5.4和Claude Opus 4.6,综合能力全面对齐Opus 4.6。5月5日,GLM-5.1 Day 0上线华为云。5月12日,智谱发布GLM-5V-Turbo原生多模态模型,自研CogViT视觉编码器,采用多模态多Token预测(MMTP),实现视觉理解与编程能力的深度融合,支持20万上下文,可自主浏览网站、解析图表生成报告。5月22日,智谱发布GLM-5.1高速版API,输出速度达400 tokens/s,刷新全球大模型厂商API速度上限,由GLM团队与TileRT团队联合打造,通过推理引擎、调度系统、基础设施三层优化实现。当日智谱股价一度涨超30%,市值站上5000亿港元。此外,智谱还推进了清影2.0视频生成(1080P、10秒、音效匹配CogSound),推理成本再降30%。
阶跃星辰:Step 3.7 Flash开源+Pre-IPO轮25亿美元融资
5月29日,阶跃星辰发布并开源Step 3.7 Flash,专为生产级Agent打造。模型采用稀疏MoE架构,总参数196B+1.8B(ViT),激活参数仅11B,最高生成速度400 Tokens/s,支持256K上下文。其核心能力包括:原生多模态理解(直接处理UI界面、图表、文档)、联网与视觉搜索增强、高可靠工具调用与编排、兼容Claude Code/OpenClaw/Hermes Agent等主流框架。基准测试方面,ClawEval-1.1得分67.1,SimpleVQA Search 79.2分居榜首,SWE-PRO 56.3分,Toolathlon 49.5%。此前Step 3.5 Flash已登顶OpenRouter OpenClaw调用量月榜全球第一。此外,阶跃星辰在5月被曝完成近25亿美元Pre-IPO轮融资,创国内大模型行业单轮融资纪录,香港投资管理有限公司为其唯一投资的大模型公司,公司累计发布38款基座模型(31款为多模态),与OPPO、荣耀等手机品牌合作覆盖国内约60%头部品牌,累计装机量超4200万台。
原创文章,作者:志斌,如若转载,请注明出处:http://www.damoai.com.cn/archives/15855